地学前缘 ›› 2024, Vol. 31 ›› Issue (3): 530-540.DOI: 10.13745/j.esf.sf.2023.9.56
• 人工智能与地质应用 • 上一篇
苏恺明1,2( ), 徐耀辉1,2,*(), 徐旺林3, 张月巧3, 白斌3, 李阳1,2, 严刚1,2
), 徐耀辉1,2,*(), 徐旺林3, 张月巧3, 白斌3, 李阳1,2, 严刚1,2
收稿日期:2023-05-31
修回日期:2023-09-06
出版日期:2024-05-25
发布日期:2024-05-25
通信作者:
*徐耀辉(1972—),男,教授,博士生导师,主要从事油气地球化学综合研究。E-mail: 作者简介:苏恺明(1994—),男,讲师,主要从事油气地球化学与机器学习的学科交叉研究。E-mail: sukaiming@yangtzeu.edu.cn
基金资助:
SU Kaiming1,2(), XU Yaohui1,2,*(), XU Wanglin3, ZHANG Yueqiao3, BAI Bin3, LI Yang1,2, YAN Gang1,2
Received:2023-05-31
Revised:2023-09-06
Online:2024-05-25
Published:2024-05-25
摘要:
鄂尔多斯盆地延长组发育多套潜在的烃源岩,但不同烃源岩之间生物标志物特征相似,常规油源对比方法效果不佳,相关认识长期存在争议。基于这样的问题,本文提出了一种基于深度学习的油源对比方案,将人工智能方法应用于油源对比研究,所开展的工作和认识有:(1)以延长组不同层位大量泥岩、页岩样品的42种生物标志物参数作为学习数据,构建了一种识别未知样品油源类别的深度神经网络模型,对长7泥页岩、长8—长10泥页岩的判别正确率分别达到了79.6%和83.0%,实现了延长组主要烃源岩生烃产物的有效区分;(2)通过模型分析了大量砂岩、原油样品的油源分类,统计了不同烃源岩对于延长组各个油层组原油的贡献比例,总结了它们的分布规律;(3)基于目前较为先进的置换特征重要性(PFI)算法,对所得模型进行了敏感性分析,初步揭示了延长组两类主要烃源岩的生物标志物差异。本文对于人工智能方法、技术在石油分子地球化学领域的发展具有积极的参考价值。
中图分类号:
苏恺明, 徐耀辉, 徐旺林, 张月巧, 白斌, 李阳, 严刚. 鄂尔多斯盆地延长组多油源贡献比例与分布规律:基于机器学习与可解释性研究[J]. 地学前缘, 2024, 31(3): 530-540.
SU Kaiming, XU Yaohui, XU Wanglin, ZHANG Yueqiao, BAI Bin, LI Yang, YAN Gang. Contribution ratio and distribution patterns of multiple oil sources in the Yanchang Formation of the Ordos Basin: A study utilizing machine learning and interpretability techniques[J]. Earth Science Frontiers, 2024, 31(3): 530-540.

图1 采样井位置及长7延长组沉积相、砂体展布
Fig.1 Well sampling locations, sedimentary facies, and distribution of sand bodies in the Chang 7 oil group of the Yanchang Formation

图2 C30重排藿烷(C30*)丰度异常的样品及其与成熟度参数之间的关联
Fig.2 Samples exhibiting abnormal abundance of C30 rearranged-hopanes (C30*) and their correlation with maturity parameters

图3 延长组地层柱状图及油气系统(据文献[30-31])
Fig.3 Stratigraphic column and petroleum system of the Yanchang Formation. Adapted from [30-31].
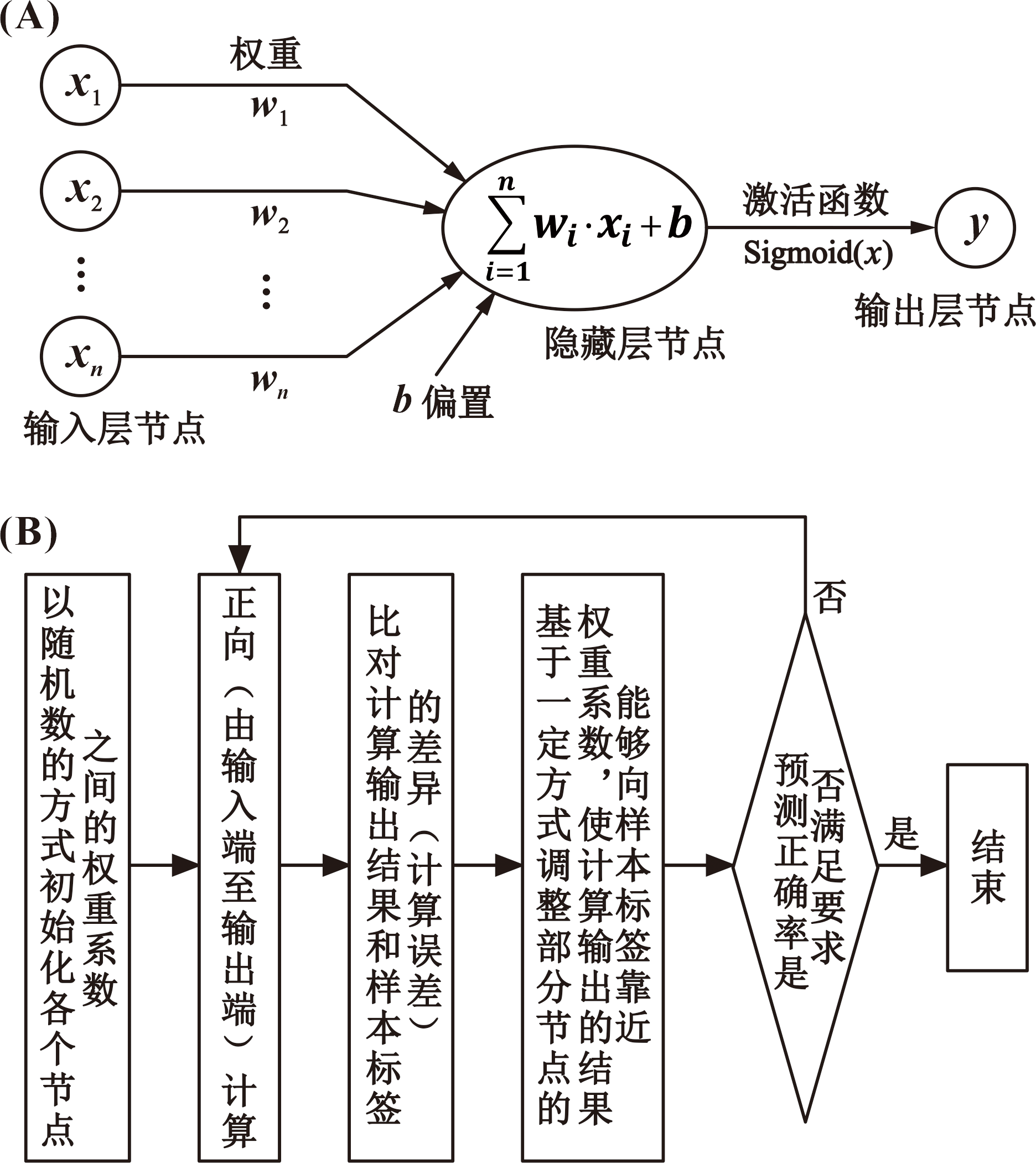
图4 多层感知器(MLP)的计算单元(A)及神经网络的训练流程(B)(A据文献[37];B据文献[36-37])
Fig.4 Computing unit (A, adapted from [37]) of the Multilayer Perceptron (MLP) and training process of the neural network (B, adapted from [36-37])
| 化合物系列 | 生物标志物参数 |
|---|---|
| 萜烷系列 | C29βα/C29αβ、C30βα/C30αβ、Ga/C30αβ、Ts/C30αβ、C30*/C30αβ、C30*/C29Ts、Ts/(Ts+Tm)、C29αβ/C30αβ、ΣC19~26TT/C30αβ、C24TET/C30αβ、C23TT/C30αβ、C29Ts/(C29Ts+C29αβ)、C31αβ22S/(22S+22R)、C32αβ22S/(22S+22R)、C3322S/(22S+22R)、C3422S/(22S+22R)、Ga/C31αβ、C19TT/C23TT、C20TT/C23TT、C21TT/C23TT、C22TT/C21TT、C24TT/C23TT、C26TT/C25TT、C24TET/C23TT、C24TET/C26TT、ETR、(C19TT+C20TT)/(C23TT+C24TT)、(C31αβ+C32αβ)/(C33αβ+C34αβ)和三环萜烷/(三环萜烷+藿烷) |
| 甾烷系列 | C29ββ/(αα+ββ)、C2920S/(20R+20S)、C27/C27~29、C28/C27~29、C29/C27~29、C28/C29、重排甾烷C2720S/(20S+20R)、重排甾烷C2920S/(20S+20R)、重排甾烷/甾烷、(孕甾烷+升孕甾烷)/甾烷、C27αα20R/C29αα20R和升孕甾烷/孕甾烷 |
| 其他 | 甾烷/藿烷 |
表1 作为特征数据变量的生物标志物参数
Table 1 Biomarker parameters selected as characteristic variables for feature data
| 化合物系列 | 生物标志物参数 |
|---|---|
| 萜烷系列 | C29βα/C29αβ、C30βα/C30αβ、Ga/C30αβ、Ts/C30αβ、C30*/C30αβ、C30*/C29Ts、Ts/(Ts+Tm)、C29αβ/C30αβ、ΣC19~26TT/C30αβ、C24TET/C30αβ、C23TT/C30αβ、C29Ts/(C29Ts+C29αβ)、C31αβ22S/(22S+22R)、C32αβ22S/(22S+22R)、C3322S/(22S+22R)、C3422S/(22S+22R)、Ga/C31αβ、C19TT/C23TT、C20TT/C23TT、C21TT/C23TT、C22TT/C21TT、C24TT/C23TT、C26TT/C25TT、C24TET/C23TT、C24TET/C26TT、ETR、(C19TT+C20TT)/(C23TT+C24TT)、(C31αβ+C32αβ)/(C33αβ+C34αβ)和三环萜烷/(三环萜烷+藿烷) |
| 甾烷系列 | C29ββ/(αα+ββ)、C2920S/(20R+20S)、C27/C27~29、C28/C27~29、C29/C27~29、C28/C29、重排甾烷C2720S/(20S+20R)、重排甾烷C2920S/(20S+20R)、重排甾烷/甾烷、(孕甾烷+升孕甾烷)/甾烷、C27αα20R/C29αα20R和升孕甾烷/孕甾烷 |
| 其他 | 甾烷/藿烷 |
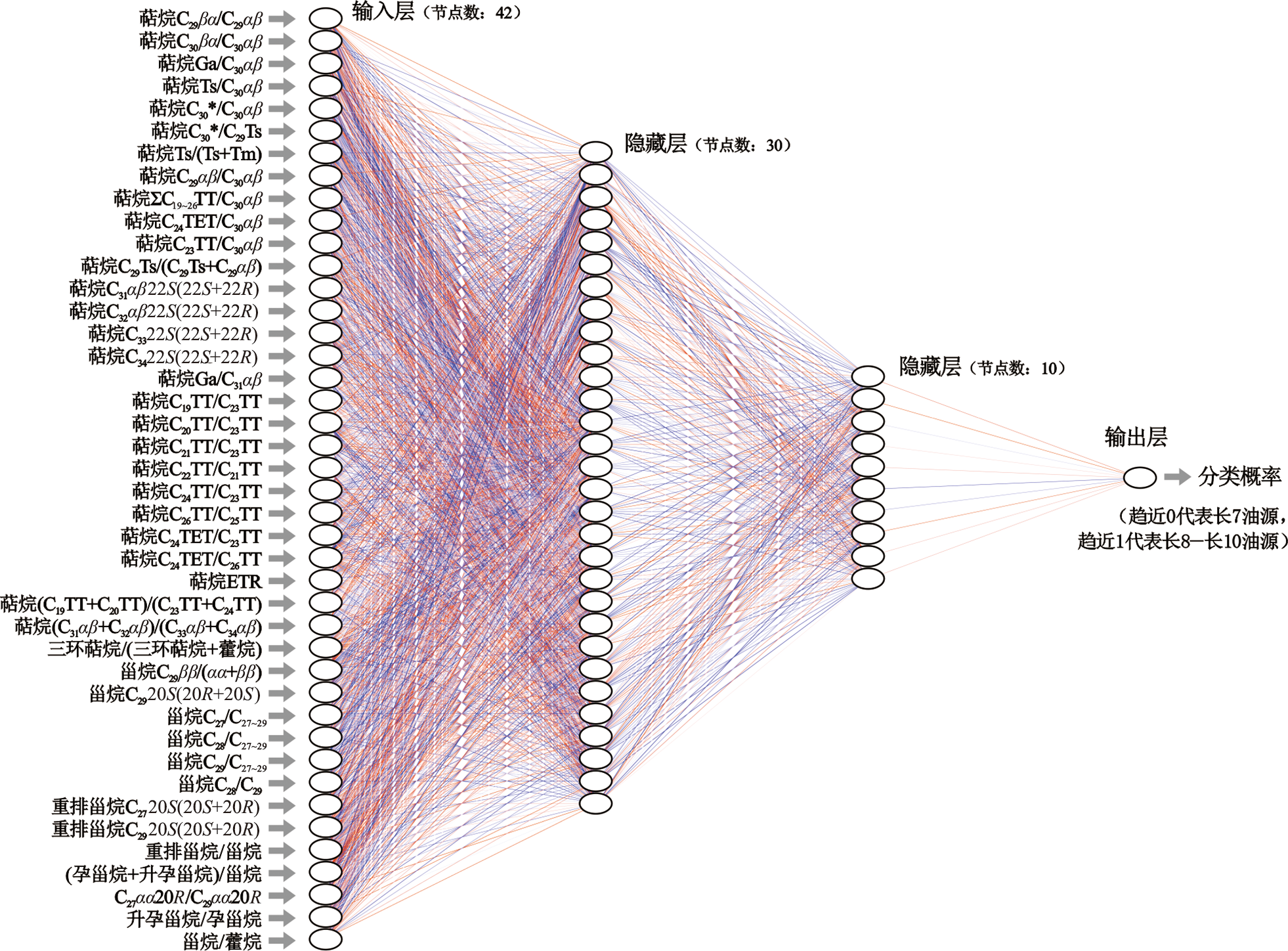
图5 用于本文油源分类问题的深度MLP神经网络
Fig.5 Deep MLP neural network used for oil source classification in this study

图6 分类模型的测试准确率箱线图
Fig.6 Box plot showing the test accuracy of the classification model
| 层位 (油层组) | 长7油源 样品数/个 | 长8—长10油 源样品数/个 | 长7烃源岩 贡献率/% | 长8—长10烃 源岩贡献率/% |
|---|---|---|---|---|
| 长7及 以上层位 | 17 | 0 | 100 | 0 |
| 长8 | 34 | 12 | 74 | 26 |
| 长9 | 25 | 13 | 66 | 34 |
| 长10 | 7 | 4 | 64 | 36 |
| 总计 | 83 | 29 | 74 | 26 |
表2 神经网络模型对于砂岩、原油样品的分析结果统计
Table 2 Analysis results of sandstone and oil samples using the neural network model
| 层位 (油层组) | 长7油源 样品数/个 | 长8—长10油 源样品数/个 | 长7烃源岩 贡献率/% | 长8—长10烃 源岩贡献率/% |
|---|---|---|---|---|
| 长7及 以上层位 | 17 | 0 | 100 | 0 |
| 长8 | 34 | 12 | 74 | 26 |
| 长9 | 25 | 13 | 66 | 34 |
| 长10 | 7 | 4 | 64 | 36 |
| 总计 | 83 | 29 | 74 | 26 |

图7 两类油源样品及长7、长9烃源岩的平面分布图(据文献[2,52])
Fig.7 Planar distribution of two types of oil sources and source rocks of Chang 7 and Chang 9. Adapted from [2,52].

图8 对某一参数(列)的数据进行随机置换、打乱
Fig.8 Random replacement and shuffling of data of a specific parameter (column)
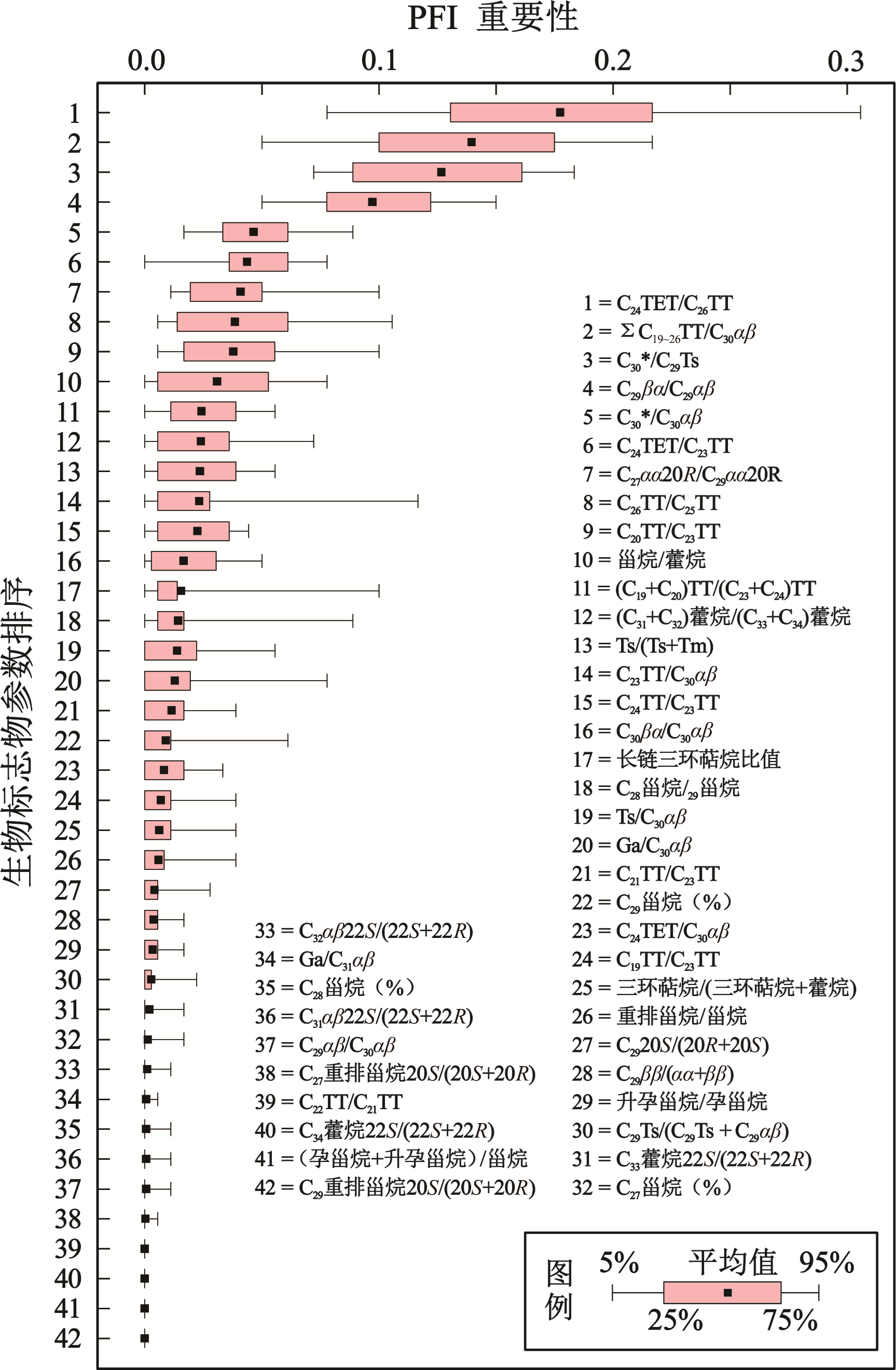
图9 各生物标志物参数的PFI箱线图
Fig.9 Box plot of Permutation Feature Importance (PFI) for each biomarker parameter
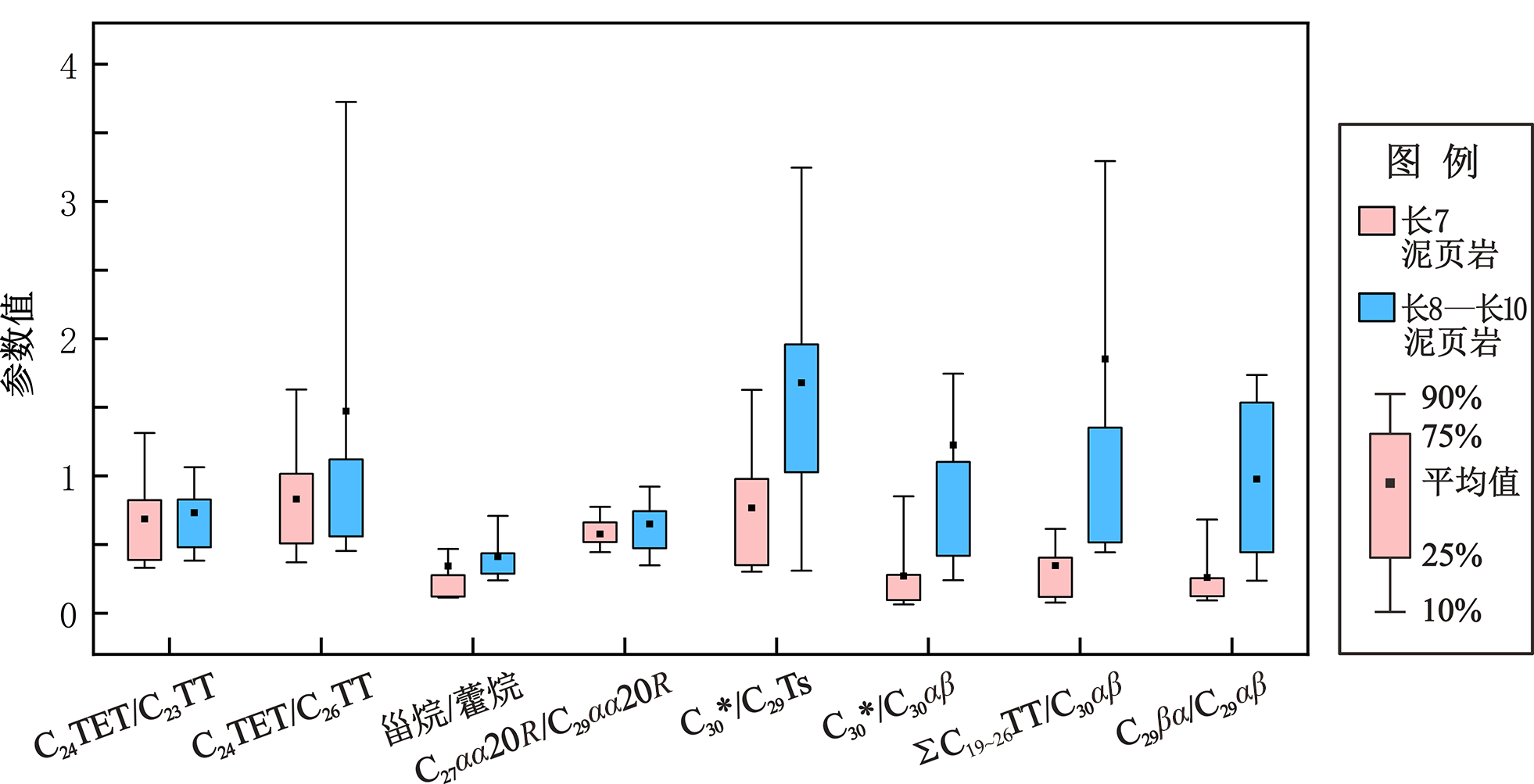
图10 长7泥页岩与长8—长10泥页岩生物标志物参数统计对比
Fig.10 Statistical comparison of biomarker parameters between Chang 7 mudstone/shale and Chang 8-Chang 10 mudstone/shale
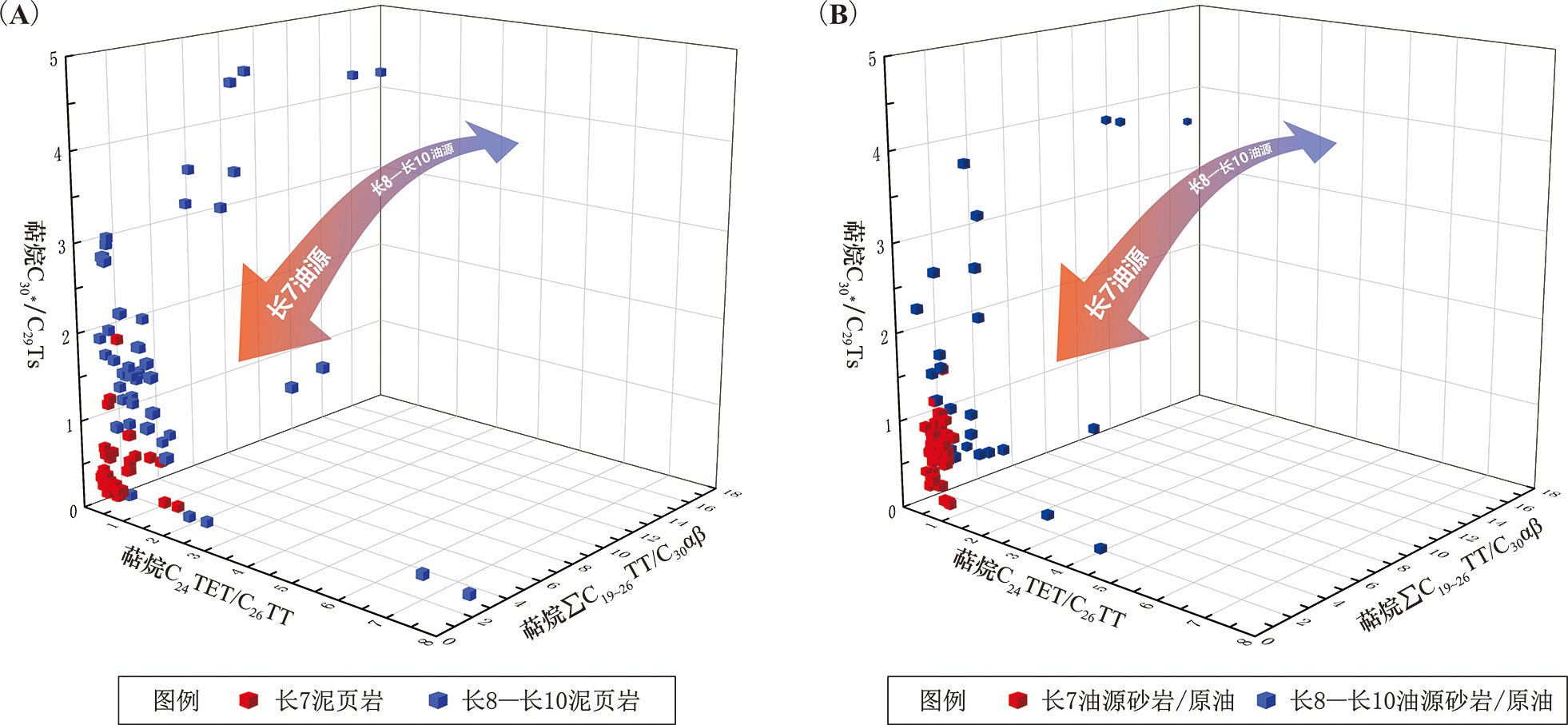
图11 图9中重要性最高的3个生物标志物参数之间的三维散点图
Fig.11 3D scatter plots among the top three most important biomarker parameters from Fig.9
| [1] |
付金华, 李士祥, 牛小兵, 等. 鄂尔多斯盆地三叠系长7段页岩油地质特征与勘探实践[J]. 石油勘探与开发, 2020, 47(5): 870-883.
DOI |
| [2] |
杨华, 牛小兵, 徐黎明, 等. 鄂尔多斯盆地三叠系长7段页岩油勘探潜力[J]. 石油勘探与开发, 2016, 43(4): 511-520.
DOI |
| [3] | 陈建平, 黄第藩. 鄂尔多斯盆地东南缘煤矿侏罗系原油油源[J]. 沉积学报, 1997, 15(2): 100-104. |
| [4] | 侯林慧, 彭平安, 于赤灵, 等. 鄂尔多斯盆地姬塬—西峰地区原油地球化学特征及油源分析[J]. 地球化学, 2007, 36(5): 497-506. |
| [5] | 王传远, 段毅, 杜建国, 等. 鄂尔多斯盆地三叠系延长组原油中性含氮化合物的分布特征及油气运移[J]. 油气地质与采收率, 2009, 16(3): 7-10. |
| [6] | 郭艳琴, 李文厚, 陈全红, 等. 鄂尔多斯盆地安塞—富县地区延长组—延安组原油地球化学特征及油源对比[J]. 石油与天然气地质, 2006, 27(2): 218-224. |
| [7] | 张文正, 杨华, 李善鹏. 鄂尔多斯盆地长91湖相优质烃源岩成藏意义[J]. 石油勘探与开发, 2008, 35(5): 557-562. |
| [8] | 张景廉. 油气“倒灌”论质疑[J]. 岩性油气藏, 2009, 21(3): 122-128. |
| [9] | 李传亮. 油气倒灌不可能发生[J]. 岩性油气藏, 2009, 21(1): 6-10. |
| [10] | 张文正, 杨华, 候林慧, 等. 鄂尔多斯盆地延长组不同烃源岩17α(H)-重排藿烷的分布及其地质意义[J]. 中国科学(D辑: 地球科学), 2009, 39(10): 1438-1445. |
| [11] | 邹贤利, 陈世加, 路俊刚, 等. 鄂尔多斯盆地延长组烃源岩17α(H)-重排藿烷的组成及分布研究[J]. 地球化学, 2017, 46(3): 252-261. |
| [12] | 张敏, 李谨, 陈菊林. 热力作用对烃源岩中重排藿烷类化合物形成的作用[J]. 沉积学报, 2018, 36(5): 1033-1039. |
| [13] | 李红磊, 张敏, 姜连, 等. 利用芳烃参数研究煤系烃源岩中重排藿烷成因[J]. 沉积学报, 2016, 34(1): 191-199. |
| [14] | 李姗姗, 白斌, 严刚, 等. 泥页岩热模拟排出油与滞留油中17α(H)-重排藿烷的成熟度指示规律[J]. 石油实验地质, 2022, 44(5): 887-895. |
| [15] |
付锁堂, 金之钧, 付金华, 等. 鄂尔多斯盆地延长组7段从致密油到页岩油认识的转变及勘探开发意义[J]. 石油学报, 2021, 42(5): 561-569.
DOI |
| [16] |
付金华, 牛小兵, 李明瑞, 等. 鄂尔多斯盆地延长组7段3亚段页岩油风险勘探突破与意义[J]. 石油学报, 2022, 43(6): 760-769.
DOI |
| [17] | 范柏江, 晋月, 师良, 等. 鄂尔多斯盆地中部三叠系延长组7段湖相页岩油勘探潜力[J]. 石油与天然气地质, 2021, 42(5): 1078-1088. |
| [18] | 王龙, 陈培元, 孙福亭, 等. 鄂尔多斯盆地彭阳地区延长组、延安组原油地球化学特征与油源对比[J]. 海洋地质前沿, 2019, 35(12): 49-54. |
| [19] | PETERS K E, WALTERS C C, MOLDOWAN J M. The biomarker guide: Volume 2, biomarkers and isotopes in petroleum systems and Earth history[M]. 2nd ed. New York: Cambridge University Press, 2007. |
| [20] | SU K M, CHEN S J, HOU Y T, et al. Application of factor analysis to investigating molecular geochemical characteristics of organic matter and oil sources: an exploratory study of the Yanchang Formation in the Ordos Basin, China[J]. Journal of Petroleum Science and Engineering, 2022, 208: 109668. |
| [21] | 王遥平. 基于化学计量学的油气源对比与实例研究[D]. 广州: 中国科学院广州地球化学研究所, 2019. |
| [22] | ALIZADEH B, ALIPOUR M, CHEHRAZI A, et al. Chemometric classification and geochemistry of oils in the Iranian sector of the southern Persian Gulf Basin[J]. Organic Geochemistry, 2017, 111: 67-81. |
| [23] | 王遥平, 邹艳荣, 史健婷, 等. 化学计量学在油-油和油-源对比中的应用现状及展望[J]. 天然气地球科学, 2018, 29(4): 452-467. |
| [24] | NIU X X, SUEN C Y. A novel hybrid CNN-SVM classifier for recognizing handwritten digits[J]. Pattern Recognition, 2012, 45(4): 1318-1325. |
| [25] | LIN J D, WU X Y, CHAI Y, et al. Structure optimization of convolutional neural networks: a survey[J]. Acta Automatica Sinica, 2020, 46(1): 24-37. |
| [26] | 韩玉娇. 基于AdaBoost机器学习算法的大牛地气田储层流体智能识别[J]. 石油钻探技术, 2022, 50(1): 112-118. |
| [27] | KOESHIDAYATULLAH A, MORSILLI M, LEHRMANN D J, et al. Fully automated carbonate petrography using deep convolutional neural networks[J]. Marine and Petroleum Geology, 2020, 122: 104687. |
| [28] |
杜炳毅, 张广智, 王磊, 等. 基于机器学习的复杂储层微小断裂系统识别方法研究与应用[J]. 石油物探, 2021, 60(4): 621-631.
DOI |
| [29] | 周永章, 左仁广, 刘刚, 等. 数学地球科学跨越发展的十年: 大数据、人工智能算法正在改变地质学[J]. 矿物岩石地球化学通报, 2021, 40(3): 556-573. |
| [30] | QU H J, YANG B, GAO S L, et al. Controls on hydrocarbon accumulation by facies and fluid potential in large-scale lacustrine petroliferous basins in compressional settings: a case study of the Mesozoic Ordos Basin, China[J]. Marine and Petroleum Geology, 2020, 122: 104668. |
| [31] | ZHANG K, LIU R, LIU Z J. Sedimentary sequence evolution and organic matter accumulation characteristics of the Chang 8-Chang 7 members in the Upper Triassic Yanchang Formation, Southwest Ordos Basin, central China[J]. Journal of Petroleum Science and Engineering, 2021, 196: 107751. |
| [32] | LI Q, WU S H, XIA D L, et al. Major and trace element geochemistry of the lacustrine organic-rich shales from the Upper Triassic Chang 7 member in the southwestern Ordos Basin, China: implications for paleoenvironment and organic matter accumulation[J]. Marine and Petroleum Geology, 2020, 111: 852-867. |
| [33] | 邓南涛, 张枝焕, 鲍志东, 等. 鄂尔多斯盆地南部延长组有效烃源岩地球化学特征及其识别标志[J]. 中国石油大学学报(自然科学版), 2013, 37(2): 135-145. |
| [34] | 姚泾利, 高岗, 庞锦莲, 等. 鄂尔多斯盆地陇东地区延长组非主力有效烃源岩发育特征[J]. 地学前缘, 2013, 20(2): 116-124. |
| [35] | 周世颖. 鄂尔多斯盆地周家湾—高桥地区长7—长9烃源岩评价及油源研究[D]. 成都: 西南石油大学, 2017. |
| [36] | MALEKI F, OVENS K, NAJAFIAN K, et al. Overview of machine learning, part 1: fundamentals and classic approaches[J]. Neuroimaging Clinics of North America, 2020, 30(4): e17-e32. |
| [37] | 周永章, 张良均, 张奥多, 等. 地球科学大数据挖掘与机器学习[M]. 广州: 中山大学出版社, 2018. |
| [38] | BARROW H. Connectionism and neural networks[M]//BODEN M A. Handbook of perception and cognition. New York: Academic Press, 1996: 135-155. |
| [39] | SAIKIA P, BARUAH R D, SINGH S K, et al. Artificial neural networks in the domain of reservoir characterization: a review from shallow to deep models[J]. Computers & Geosciences, 2020, 135: 104357. |
| [40] | 李苍柏, 肖克炎, 李楠, 等. 支持向量机、随机森林和人工神经网络机器学习算法在地球化学异常信息提取中的对比研究[J]. 地球学报, 2020, 41(2): 309-319. |
| [41] | 王琪琪, 汤井田, 张良, 等. 利用多层感知机的地震数据去噪[J]. 石油地球物理勘探, 2020, 55(2): 272-281. |
| [42] | LESHNO M, LIN V Y, PINKUS A, et al. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function[J]. Neural Networks, 1993, 6(6): 861-867. |
| [43] | 黄毅, 段修生, 孙世宇, 等. 基于改进sigmoid激活函数的深度神经网络训练算法研究[J]. 计算机测量与控制, 2017, 25(2): 126-129. |
| [44] |
邓建国, 张素兰, 张继福, 等. 监督学习中的损失函数及应用研究[J]. 大数据, 2020, 6(1): 60-80.
DOI |
| [45] | KINGMA D P, BA J. Adam: A method for stochastic optimization[C]//Proceeding of the 3rd international conference for learning Representations (ICLR 2015). San Diego: ArXiv, 2015. |
| [46] | ENEOGWE C, EKUNDAYO O. Geochemical correlation of crude oils in the NW Niger Delta, Nigeria[J]. Journal of Petroleum Geology, 2003, 26(1): 95-103. |
| [47] | AHMED M, VOLK H, ALLAN T, et al. Origin of oils in the Eastern Papuan Basin, Papua New Guinea[J]. Organic Geochemistry, 2012, 53: 137-152. |
| [48] | XIAO H, LI M J, LIU J G, et al. Oil-oil and oil-source rock correlations in the Muglad Basin, Sudan and South Sudan: new insights from molecular markers analyses[J]. Marine and Petroleum Geology, 2019, 103: 351-365. |
| [49] | SPAAK G, EDWARDS D S, FOSTER C B, et al. Geochemical characteristics of early Carboniferous petroleum systems in Western Australia[J]. Marine and Petroleum Geology, 2020, 113: 104073. |
| [50] | ANYSZ H, ZBICIAK A, IBADOV N. The influence of input data standardization method on prediction accuracy of artificial neural networks[J]. Procedia Engineering, 2016, 153: 66-70. |
| [51] | WEI X, ZHANG L L, YANG H Q, et al. Machine learning for pore-water pressure time-series prediction: application of recurrent neural networks[J]. Geoscience Frontiers, 2021, 12(1): 453-467. |
| [52] | 李吉君, 吴慧, 卢双舫, 等. 鄂尔多斯盆地长9烃源岩发育与排烃效率[J]. 吉林大学学报(地球科学版), 2012(增刊1): 26-32. |
| [53] | GEVREY M, DIMOPOULOS I, LEK S. Two-way interaction of input variables in the sensitivity analysis of neural network models[J]. Ecological Modelling, 2006, 195(1/2): 43-50. |
| [54] | BREIMAN L. Random Forests[J]. Machine Learning, 2001, 45: 5-32. |
| [55] |
MI X, ZOU B, ZOU F, et al. Permutation-based identification of important biomarkers for complex diseases via machine learning models[J]. Nature Communications, 2021, 12: 3008.
DOI PMID |
| [56] | RAMIREZ S G, HALES R C, WILLIAMS G P, et al. Extending SC-PDSI-PM with neural network regression using GLDAS data and Permutation Feature Importance[J]. Environmental Modelling & Software, 2022, 157: 105475. |
| [57] | LI Z, SHI H, YANG X, et al. Investigating the nonlinear relationship between surface solar radiation and its influencing factors in North China Plain using interpretable machine learning[J]. Atmospheric Research, 2022, 280: 106406. |
| [58] | VIJ A, NANJUNDAN P. Comparing strategies for post-hoc explanations in machine learning models[M]//SHAKYA S, BESTAK R, PALANISAMY R, et al. Mobile computing and sustainable informatics lecture notes on data engineering and communications technologies. Singapore: Springer Nature Singapore, 2021: 585-592. |
| [59] | KRUGE M A, HUBERT J F, AKES R J, et al. Biological markers in Lower Jurassic synrift lacustrine black shales, Hartford Basin, Connecticut, U.S.A.[J]. Organic Geochemistry, 1990, 15(3): 281-289. |
| [60] | CONNAN J, BOUROULLEC J, DESSORT D, et al. The microbial input in carbonate-anhydrite facies of a sabkha palaeoenvironment from Guatemala: a molecular approach[J]. Organic Geochemistry, 1986, 10(1/2/3): 29-50. |
| [1] | 张焕宝, 贺海洋, 杨仕教, 李亚林, 毕文军, 韩世礼, 郭钦鹏, 杜青. 基于机器学习的埃达克质岩构造背景判别研究[J]. 地学前缘, 2024, 31(4): 417-428. |
| [2] | 刘洋, 李三忠, 钟世华, 郭广慧, 刘嘉情, 牛警徽, 薛梓萌, 周建平, 董昊, 索艳慧. 机器学习:海底矿产资源智能勘探的新途径[J]. 地学前缘, 2024, 31(3): 520-529. |
| [3] | 张利军, 鲁文豪, 张建东, 彭光雄, 卜建财, 唐凯, 谢渐成, 徐质彬, 杨海燕. 基于深度学习的镜下岩石、矿物薄片识别[J]. 地学前缘, 2024, 31(3): 498-510. |
| [4] | 徐哈宁, 邓居智, 肖慧. 基于邻近域特征的堆积层滑坡多维地电信息成像监测技术研究[J]. 地学前缘, 2023, 30(6): 473-484. |
| [5] | 王子烨, 左仁广. 基于多源数据融合的喜马拉雅淡色花岗岩识别[J]. 地学前缘, 2023, 30(5): 216-226. |
| [6] | 宋轩宇, 许民, 康世昌, 孙立平. 基于机器学习的冰冻圈典型流域水文过程模拟研究[J]. 地学前缘, 2023, 30(4): 451-469. |
| [7] | 朱紫怡, 周飞, 王瑀, 周统, 侯照亮, 邱昆峰. 基于机器学习的锆石成因分类研究[J]. 地学前缘, 2022, 29(5): 464-475. |
| [8] | 胡义明, 陈腾, 罗序义, 唐超, 梁忠民. 基于机器学习模型的淮河流域中长期径流预报研究[J]. 地学前缘, 2022, 29(3): 284-291. |
| [9] | 张振杰, 成秋明, 杨玠, 武国朋, 葛云钊. 机器学习与成矿预测:以闽西南铁多金属矿预测为例[J]. 地学前缘, 2021, 28(3): 221-235. |
| [10] | 左仁广. 基于数据科学的矿产资源定量预测的理论与方法探索[J]. 地学前缘, 2021, 28(3): 49-55. |
| [11] | 左仁广. 勘查地球化学数据挖掘与弱异常识别[J]. 地学前缘, 2019, 26(4): 67-75. |
| [12] | 洪瑾,甘成势,刘洁. 基于机器学习的洋岛玄武岩主量元素预测稀土元素[J]. 地学前缘, 2019, 26(4): 45-54. |
| [13] | 章宝月,孙建鹍,罗熊,金维浚,王龙,杜雪亮,陈万峰,杜君,张旗,朱月琴. 三类构造背景辉长岩单斜辉石主量元素和微量元素的数据分析研究[J]. 地学前缘, 2019, 26(4): 33-44. |
| [14] | 罗建民,张旗. 大数据开创地学研究新途径:查明相关关系,增强研究可行性[J]. 地学前缘, 2019, 26(4): 6-12. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||