地学前缘 ›› 2025, Vol. 32 ›› Issue (5): 466-483.DOI: 10.13745/j.esf.sf.2025.9.3
刘美玉1( ), 吴玮1,*(), 王汇2, 罗伟儿1, 吴娟娟1, 郭旭东1
), 吴玮1,*(), 王汇2, 罗伟儿1, 吴娟娟1, 郭旭东1
收稿日期:2025-02-20
修回日期:2025-07-30
出版日期:2025-09-25
发布日期:2025-10-14
通信作者:
吴玮
作者简介:刘美玉(1992—),女,博士,助理研究员,主要从事自然灾害监测评估研究与应用工作。E-mail: liumeiyu@ndrccc.org.cn
基金资助:
LIU Meiyu1(), WU Wei1,*(), WANG Hui2, LUO Weier1, WU Juanjuan1, GUO Xudong1
Received:2025-02-20
Revised:2025-07-30
Online:2025-09-25
Published:2025-10-14
Contact:
WU Wei
摘要:
机器学习方法是预测地震诱发滑坡风险的重要方法,可显著提高震后风险评估的效率。为探究不同机器学习模型对地震滑坡危险性预测的效果,本研究以2023年甘肃积石山Ms 6.2地震VII度区为研究区域,利用中国西部地区8次地震诱发滑坡的数据,制作8次地震异构训练集和8次地震传统训练集,并从中挑选出与积石山地震最为相似的4次地震,制作4次地震异构训练集和4次地震传统训练集,对3种主流机器学习模型——随机森林(RF)、人工神经网络(ANN)和极端梯度提升(XGBoost)进行对比评估。结果显示,使用8次地震异构训练集的随机森林模型表现最佳,AUC值最高,预测精度最佳。使用8次地震传统训练集的极端梯度提升和人工神经网络模型也表现良好,AUC值高于其他数据集。反之,基于地震相似性所构建的4次地震数据集训练的模型均显示出较低的准确性,表明样本大小对模型性能的影响大于样本相似性。此外,所有使用传统4次地震数据集的模型均表现出过拟合现象,进一步说明训练集规模的重要性。本研究为提高地震诱发滑坡预测的准确性提供了关于训练数据和模型选择的方法,可为应急响应和灾害风险管理工作提供有力支持。
中图分类号:
刘美玉, 吴玮, 王汇, 罗伟儿, 吴娟娟, 郭旭东. 训练集规模优先于相似性:机器学习模型在积石山地震滑坡预测中的比较研究[J]. 地学前缘, 2025, 32(5): 466-483.
LIU Meiyu, WU Wei, WANG Hui, LUO Weier, WU Juanjuan, GUO Xudong. Training set size takes precedence over similarity: A comparative study of machine learning models for landslide prediction in the Jishishan earthquake[J]. Earth Science Frontiers, 2025, 32(5): 466-483.

图1 研究区地理位置(同震滑坡数据)
Fig.1 Geographical location of the study area (co-seismic landslide data)

图2 模型训练选用的影响因子 a—LCD;b—Aspect;c—Slope;d—DEM;e—Fault;f—PGA;g—River;h—NDVI;i—同震滑坡。
Fig.2 Influencing factors selected for model training

图3 地震滑坡影响因子相关系数矩阵
Fig.3 Correlation coefficient matrix of influencing factors for earthquake-induced landslides

图4 随机森林模型同震滑坡易发性预测结果 a—异构4次地震训练集预测结果;b—异构8次地震训练集预测结果;c—传统4次地震训练集预测结果;d—传统8次地震训练集预测结果。
Fig.4 Prediction results of the random forest model for co-seismic landslide susceptibility
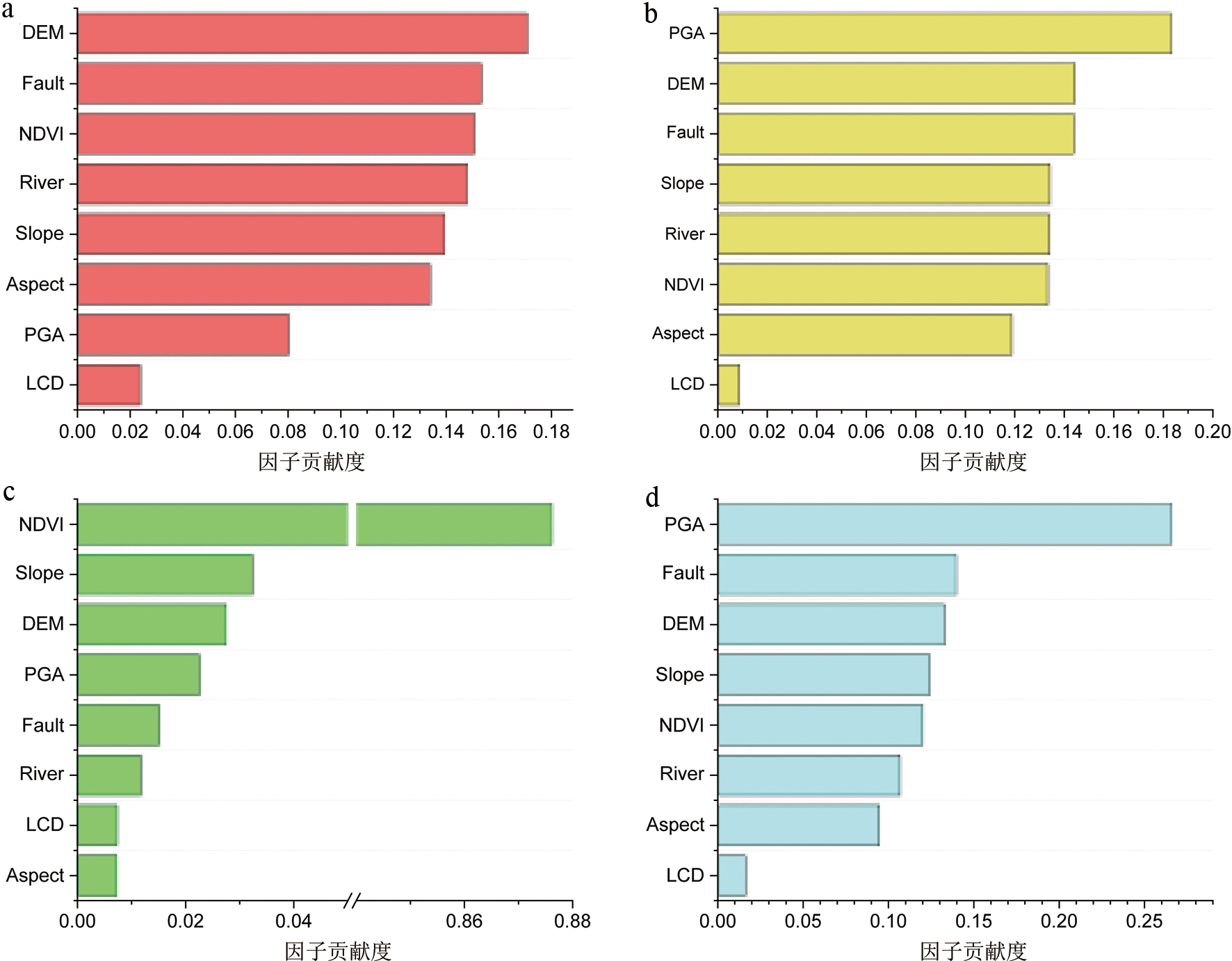
图5 随机森林模型因子贡献度 a—异构4次地震训练集因子贡献度;b—异构8次地震训练集因子贡献度;c—传统4次地震训练集因子贡献度;d—传统8次地震训练集因子贡献度。
Fig.5 Factor contribution of random forest model
| 因子 | 异构4次地震 | 异构8次地震 | 传统4次地震 | 传统8次地震 |
|---|---|---|---|---|
| LCD | 0.023 778 | 0.008 591 | 0.007 332 | 0.016 242 |
| Aspect | 0.133 877 | 0.118 729 | 0.007 290 | 0.094 656 |
| Slope | 0.139 360 | 0.134 182 | 0.032 378 | 0.124 060 |
| DEM | 0.170 792 | 0.144 311 | 0.027 497 | 0.132 693 |
| Fault | 0.153 277 | 0.143 819 | 0.015 115 | 0.139 639 |
| PGA | 0.080 306 | 0.183 184 | 0.022 557 | 0.265 930 |
| River | 0.147 946 | 0.133 952 | 0.011 720 | 0.106 703 |
| NDVI | 0.150 664 | 0.133 232 | 0.876 112 | 0.120 077 |
表1 随机森林模型因子贡献度
Table 1 Factor contribution of the random forest model
| 因子 | 异构4次地震 | 异构8次地震 | 传统4次地震 | 传统8次地震 |
|---|---|---|---|---|
| LCD | 0.023 778 | 0.008 591 | 0.007 332 | 0.016 242 |
| Aspect | 0.133 877 | 0.118 729 | 0.007 290 | 0.094 656 |
| Slope | 0.139 360 | 0.134 182 | 0.032 378 | 0.124 060 |
| DEM | 0.170 792 | 0.144 311 | 0.027 497 | 0.132 693 |
| Fault | 0.153 277 | 0.143 819 | 0.015 115 | 0.139 639 |
| PGA | 0.080 306 | 0.183 184 | 0.022 557 | 0.265 930 |
| River | 0.147 946 | 0.133 952 | 0.011 720 | 0.106 703 |
| NDVI | 0.150 664 | 0.133 232 | 0.876 112 | 0.120 077 |

图6 XGBoost模型同震滑坡易发性预测结果 a—异构4次地震训练集预测结果;b—异构8次地震训练集预测结果;c—传统4次地震训练集预测结果;d—传统8次地震训练集预测结果。
Fig.6 Prediction results of XGBoost model for co-seismic landslide susceptibility
| 因子 | 异构4次地震 | 异构8次地震 | 传统4次地震 | 传统8次地震 |
|---|---|---|---|---|
| LCD | 0.138 074 | 0.039 520 | 0.009 724 | 0.068 789 |
| Aspect | 0.071 046 | 0.021 518 | 0.001 652 | 0.037 196 |
| Slope | 0.136 052 | 0.155 870 | 0.006 470 | 0.127 573 |
| DEM | 0.147 697 | 0.107 061 | 0.005 043 | 0.089 514 |
| Fault | 0.091 351 | 0.069 240 | 0.002 893 | 0.074 135 |
| PGA | 0.186 176 | 0.508 977 | 0.000 959 | 0.470 988 |
| River | 0.088 134 | 0.048 028 | 0.002 270 | 0.050 365 |
| NDVI | 0.141 469 | 0.049 787 | 0.970 990 | 0.081 440 |
表2 XGBoost模型因子贡献度
Table 2 Factor contribution of XGBoost model
| 因子 | 异构4次地震 | 异构8次地震 | 传统4次地震 | 传统8次地震 |
|---|---|---|---|---|
| LCD | 0.138 074 | 0.039 520 | 0.009 724 | 0.068 789 |
| Aspect | 0.071 046 | 0.021 518 | 0.001 652 | 0.037 196 |
| Slope | 0.136 052 | 0.155 870 | 0.006 470 | 0.127 573 |
| DEM | 0.147 697 | 0.107 061 | 0.005 043 | 0.089 514 |
| Fault | 0.091 351 | 0.069 240 | 0.002 893 | 0.074 135 |
| PGA | 0.186 176 | 0.508 977 | 0.000 959 | 0.470 988 |
| River | 0.088 134 | 0.048 028 | 0.002 270 | 0.050 365 |
| NDVI | 0.141 469 | 0.049 787 | 0.970 990 | 0.081 440 |

图7 XGBoost模型因子贡献度 a—异构4次地震训练集因子贡献度;b—异构8次地震训练集因子贡献度;c—传统4次地震训练集因子贡献度;d—传统8次地震训练集因子贡献度。
Fig.7 Factor contribution of XGBoost model
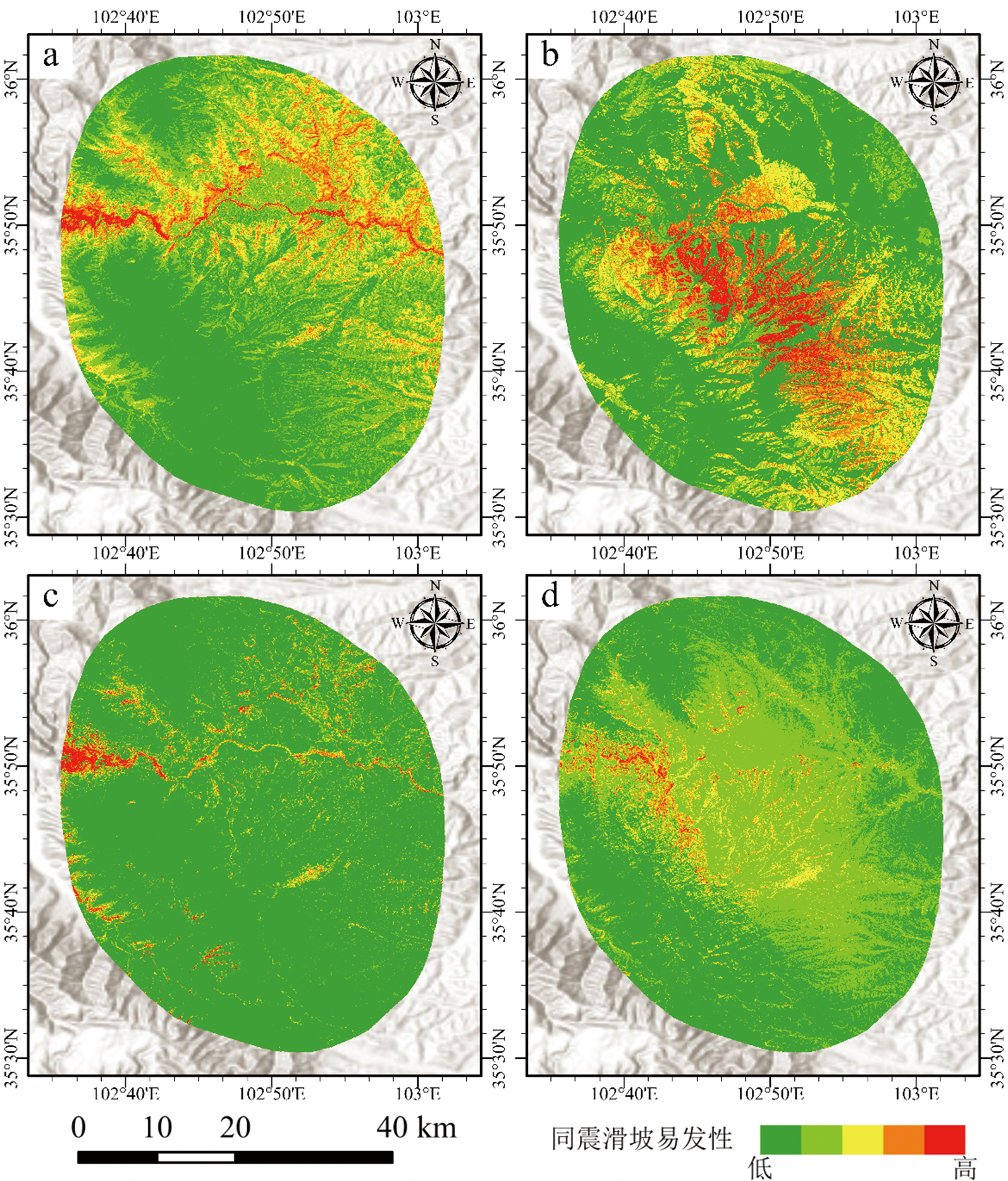
图8 人工神经网络模型同震滑坡易发性预测结果 a—异构4次地震训练集预测结果;b—异构8次地震训练集预测结果;c—传统4次地震训练集预测结果;d—传统8次地震训练集预测结果。
Fig.8 Prediction results of ANN model for co-seismic landslide susceptibility
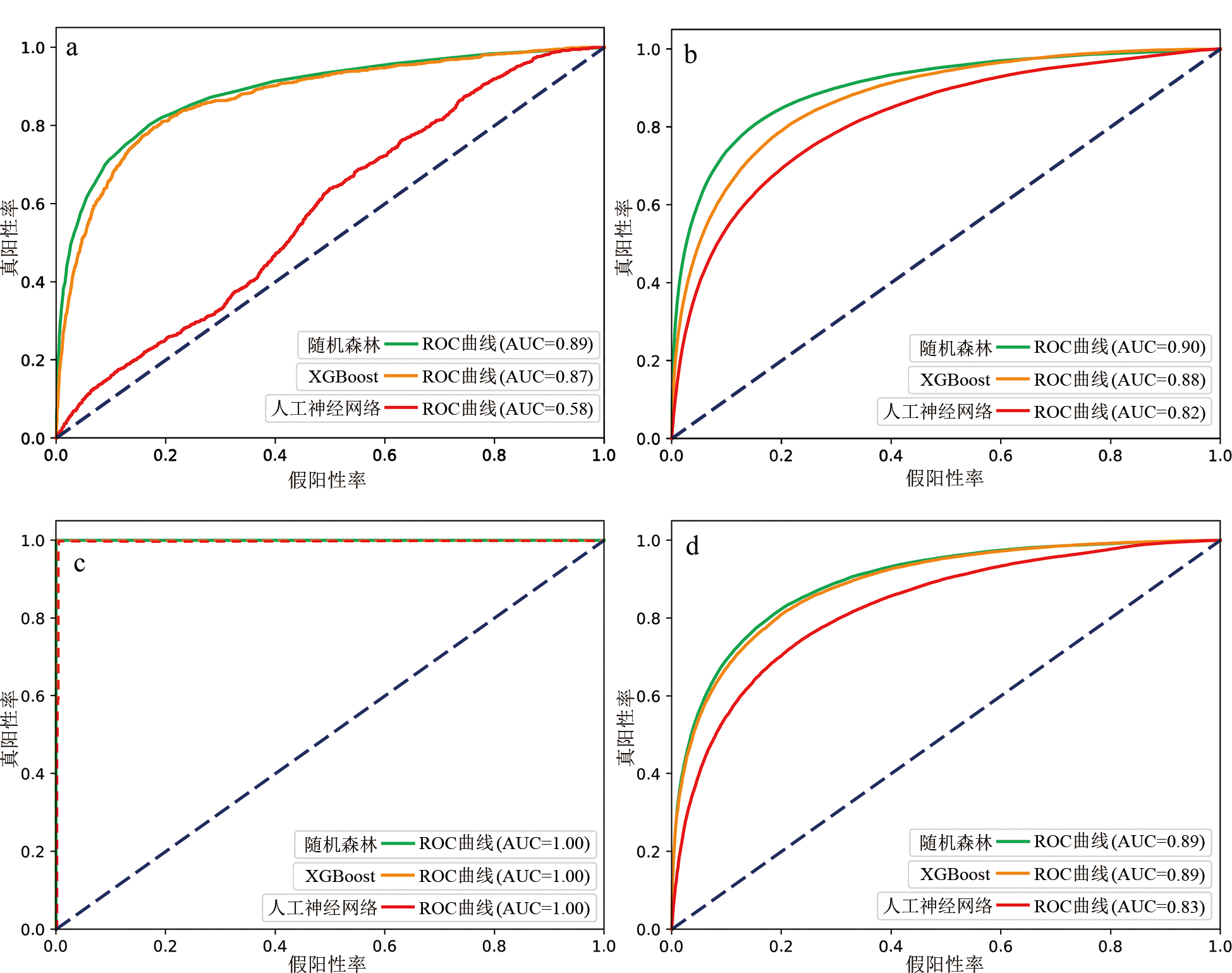
图9 3种模型4种采样策略的ROC曲线 a—异构4次地震训练集ROC曲线;b—异构8次地震训练集ROC曲线;c—传统4次地震训练集ROC曲线;d—传统8次地震训练集ROC曲线。
Fig.9 ROC curves of three models with four sampling strategies
| 模型 | 定量评估准确性/% | ||
|---|---|---|---|
| 异构4次地震 | 异构8次地震 | 传统8次地震 | |
| 随机森林 | 55.00 | 60.35 | 53.60 |
| XGBoost | 33.60 | 27.09 | 45.35 |
| 人工神经网络 | 83.84 | 22.79 | 29.65 |
表3 定量评估准确性
Table 3 Quantitative assessment of accuracy
| 模型 | 定量评估准确性/% | ||
|---|---|---|---|
| 异构4次地震 | 异构8次地震 | 传统8次地震 | |
| 随机森林 | 55.00 | 60.35 | 53.60 |
| XGBoost | 33.60 | 27.09 | 45.35 |
| 人工神经网络 | 83.84 | 22.79 | 29.65 |
| [1] | BUDIMIR M E A, ATKINSON P M, LEWIS H G. A systematic review of landslide probability mapping using logistic regression[J]. Landslides, 2015, 12(3): 419-436. |
| [2] | LEE S, PRADHAN B. Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models[J]. Landslides, 2007, 4(1): 33-41. |
| [3] | HE S W, PAN P, DAI L, et al. Application of kernel-based Fisher discriminant analysis to map landslide susceptibility in the Qinggan River delta, Three Gorges, China[J]. Geomorphology, 2012, 171/172: 30-41. |
| [4] | SAHA A, TRIPATHI L, VILLURI V G K, et al. Exploring machine learning and statistical approach techniques for landslide susceptibility mapping in Siwalik Himalayan Region using geospatial technology[J]. Environmental Science and Pollution Research, 2024, 31(7): 10443-10459. |
| [5] | KHALIL U, IMTIAZ I, ASLAM B, et al. Comparative analysis of machine learning and multi-criteria decision making techniques for landslide susceptibility mapping of Muzaffarabad district[J]. Frontiers in Environmental Science, 2022, 10: 1028373. |
| [6] | HE Q, JIANG Z Y, WANG M, et al. Landslide and wildfire susceptibility assessment in Southeast Asia using ensemble machine learning methods[J]. Remote Sensing, 2021, 13(8): 1572. |
| [7] | XI C J, HAN M, HU X W, et al. Effectiveness of Newmark-based sampling strategy for coseismic landslide susceptibility mapping using deep learning, support vector machine, and logistic regression[J]. Bulletin of Engineering Geology and the Environment, 2022, 81(5): 174. |
| [8] | TIAN Y Y, XU C, MA S Y, et al. Inventory and spatial distribution of landslides triggered by the 8th August 2017 Mw 6.5 Jiuzhaigou earthquake, China[J]. Journal of Earth Science, 2019, 30(1): 206-217. |
| [9] | CHEN W, XIE X S, PENG J B, et al. GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method[J]. Catena, 2018, 164: 135-149. |
| [10] | PRADHAN B, LEE S. Landslide risk analysis using artificial neural network model focusing on different training sites[J]. International Journal of Physical Sciences, 2009, 3(11): 1-15. |
| [11] | BISWAJEET P, SARO L. Utilization of optical remote sensing data and GIS tools for regional landslide hazard analysis using an artificial neural network model[J]. Earth Science Frontiers, 2007, 14(6): 143-151. |
| [12] | ZHANG J Y, MA X L, ZHANG J L, et al. Insights into geospatial heterogeneity of landslide susceptibility based on the SHAP-XGBoost model[J]. Journal of Environmental Management, 2023, 332: 117357. |
| [13] | KAVZOGLU T, TEKE A. Advanced hyperparameter optimization for improved spatial prediction of shallow landslides using extreme gradient boosting (XGBoost)[J]. Bulletin of Engineering Geology and the Environment, 2022, 81(5): 201. |
| [14] | HONG H Y, PRADHAN B, JEBUR M N, et al. Spatial prediction of landslide hazard at the Luxi area (China) using support vector machines[J]. Environmental Earth Sciences, 2015, 75(1): 40. |
| [15] | HUANG Y, ZHAO L. Review on landslide susceptibility mapping using support vector machines[J]. Catena, 2018, 165: 520-529. |
| [16] | MA J W, LEI D Z, REN Z Y, et al. Automated machine learning-based landslide susceptibility mapping for the Three Gorges Reservoir area, China[J]. Mathematical Geosciences, 2024, 56(5): 975-1010. |
| [17] | HONG H Y. Landslide susceptibility assessment using locally weighted learning integrated with machine learning algorithms[J]. Expert Systems with Applications, 2024, 237: 121678. |
| [18] | SHARMA N, SAHARIA M, RAMANA G V. High resolution landslide susceptibility mapping using ensemble machine learning and geospatial big data[J]. Catena, 2024, 235: 107653. |
| [19] | YOUSEFI Z, ALESHEIKH A A, JAFARI A, et al. Stacking ensemble technique using optimized machine learning models with boruta-XGBoost feature selection for landslide susceptibility mapping: a case of Kermanshah province, Iran[J]. Information, 2024, 15(11): 689. |
| [20] | TEHRANI F S, CALVELLO M, LIU Z, et al. Machine learning and landslide studies: recent advances and applications[J]. Natural Hazards, 2022, 114(2): 1197-1245. |
| [21] | POURGHASEMI H R, KARIMINEJAD N, AMIRI M, et al. Assessing and mapping multi-hazard risk susceptibility using a machine learning technique[J]. Scientific Reports, 2020, 10: 3203. |
| [22] | KORUP O, STOLLE A. Landslide prediction from machine learning[J]. Geology Today, 2014, 30(1): 26-33. |
| [23] | LIU L L, YANG C, WANG X M. Landslide susceptibility assessment using feature selection-based machine learning models[J]. Geomechanics and Engineering, 2021, 25(1): 1-16. |
| [24] | WANG Y H, WANG L Q, LIU S L, et al. A comparative study of regional landslide susceptibility mapping with multiple machine learning models[J]. Geological Journal, 2024, 59(9): 2383-2400. |
| [25] | YANG S L, TAN J Y, LUO D Y, et al. Sample size effects on landslide susceptibility models: a comparative study of heuristic, statistical, machine learning, deep learning and ensemble learning models with SHAP analysis[J]. Computers & Geosciences, 2024, 193: 105723. |
| [26] | MICHELETTI N, FORESTI L, ROBERT S, et al. Machine learning feature selection methods for landslide susceptibility mapping[J]. Mathematical Geosciences, 2014, 46: 33-57. |
| [27] | GU T, DUAN P, WANG M, et al. Effects of non-landslide sampling strategies on machine learning models in landslide susceptibility mapping[J]. Scientific Reports, 2024, 14(1): 7201. |
| [28] | ZHAO F C, MIAO F S, WU Y P, et al. Refined landslide susceptibility mapping in township area using ensemble machine learning method under dataset replenishment strategy[J]. Gondwana Research, 2024, 131: 20-37. |
| [29] | HUANG F M, XIONG H W, ZHOU X T, et al. Modelling uncertainties and sensitivity analysis of landslide susceptibility prediction under different environmental factor connection methods and machine learning models[J]. KSCE Journal of Civil Engineering, 2024, 28(1): 45-62. |
| [30] | XU S L, SONG Y X, HAO X L. A comparative study of shallow machine learning models and deep learning models for landslide susceptibility assessment based on imbalanced data[J]. Forests, 2022, 13(11): 1908. |
| [31] | KADAVI P R, LEE C W, LEE S. Application of ensemble-based machine learning models to landslide susceptibility mapping[J]. Remote Sensing, 2018, 10(8): 1252. |
| [32] | YANG C, LIU L L, HUANG F M, et al. Machine learning-based landslide susceptibility assessment with optimized ratio of landslide to non-landslide samples[J]. Gondwana Research, 2023, 123: 198-216. |
| [33] | FU X, LIU Y F, ZHU Q, et al. Reliable assessment approach of landslide susceptibility in broad areas based on optimal slope units and negative samples involving priori knowledge[J]. International Journal of Digital Earth, 2022, 15(1): 2495-2510. |
| [34] | HUSSIN H Y, ZUMPANO V, REICHENBACH P, et al. Different landslide sampling strategies in a grid-based bi-variate statistical susceptibility model[J]. Geomorphology, 2016, 253: 508-523. |
| [35] | LIU L L, ZHANG Y L, XIAO T, et al. A frequency ratio-based sampling strategy for landslide susceptibility assessment[J]. Bulletin of Engineering Geology and the Environment, 2022, 81(9): 360. |
| [36] | LE X H, CHOI C, EU S, et al. Quantitative evaluation of uncertainty and interpretability in machine learning-based landslide susceptibility mapping through feature selection and explainable AI[J]. Frontiers in Environmental Science, 2024, 12: 1424988. |
| [37] | ZHU J, BAISE L G, THOMPSON E M. An updated geospatial liquefaction model for global application[J]. Bulletin of the Seismological Society of America, 2017, 107(3): 1365-1385. |
| [38] | NOWICKI JESSEE M A, HAMBURGER M W, ALLSTADT K, et al. A global empirical model for near-real-time assessment of seismically induced landslides[J]. Journal of Geophysical Research: Earth Surface, 2018, 123(8): 1835-1859. |
| [39] | SHAO X Y, MA S Y, XU C, et al. Effects of sampling intensity and non-slide/slide sample ratio on the occurrence probability of coseismic landslides[J]. Geomorphology, 2020, 363: 107222. |
| [40] | YANG H, SHI P J, QUINCEY D, et al. A heterogeneous sampling strategy to model earthquake-triggered landslides[J]. International Journal of Disaster Risk Science, 2023, 14(4): 636-648. |
| [41] | CHANG Z L, HUANG J S, HUANG F M, et al. Uncertainty analysis of non-landslide sample selection in landslide susceptibility prediction using slope unit-based machine learning models[J]. Gondwana Research, 2023, 117: 307-320. |
| [42] | SONG Y Z, YANG D G, WU W C, et al. Evaluating landslide susceptibility using sampling methodology and multiple machine learning models[J]. ISPRS International Journal of Geo-Information, 2023, 12(5): 197. |
| [43] | CHEN S, MIAO Z L, WU L X, et al. A one-class-classifier-based negative data generation method for rapid earthquake-induced landslide susceptibility mapping[J]. Frontiers in Earth Science, 2021, 9: 609896. |
| [44] | ZHANG Y Z, YAN Q S. Landslide susceptibility prediction based on high-trust non-landslide point selection[J]. ISPRS International Journal of Geo-Information, 2022, 11(7): 398. |
| [45] | ZHU Y C, SUN D L, WEN H J, et al. Considering the effect of non-landslide sample selection on landslide susceptibility assessment[J]. Geomatics, Natural Hazards and Risk, 2024, 15: 2392778. |
| [46] | DOU H Q, HE J B, HUANG S Y, et al. Influences of non-landslide sample selection strategies on landslide susceptibility mapping by machine learning[J]. Geomatics, Natural Hazards and Risk, 2023, 14: 2285719. |
| [47] | WU B, SHI Z M, ZHENG H C, et al. Impact of sampling for landslide susceptibility assessment using interpretable machine learning models[J]. Bulletin of Engineering Geology and the Environment, 2024, 83(11): 461. |
| [48] | XU C, XU X W, YAO X, et al. Three (nearly) complete inventories of landslides triggered by the May 12, 2008 Wenchuan Mw 7.9 earthquake of China and their spatial distribution statistical analysis[J]. Landslides, 2014, 11(3): 441-461. |
| [49] | XU C, XU X W, YU G H. Landslides triggered by slipping-fault-generated earthquake on a plateau: an example of the 14 April 2010, Ms 7.1, Yushu, China earthquake[J]. Landslides, 2013, 10(4): 421-431. |
| [50] | XU C, XU X W, SHYU J B H. Database and spatial distribution of landslides triggered by the Lushan, China Mw 6.6 earthquake of 20 April 2013[J]. Geomorphology, 2015, 248: 77-92. |
| [51] | XU C, XU X W, SHYU J B H, et al. Landslides triggered by the 22 July 2013 Minxian-Zhangxian, China, Mw 5.9 earthquake: inventory compiling and spatial distribution analysis[J]. Journal of Asian Earth Sciences, 2014, 92: 125-142. |
| [52] | WU W Y, XU C, WANG X Q, et al. Landslides triggered by the 3 August 2014 Ludian (China) Mw 6.2 earthquake: an updated inventory and analysis of their spatial distribution[J]. Journal of Earth Science, 2020, 31(4): 853-866. |
| [53] | XU C, WANG S Y, XU X W, et al. A panorama of landslides triggered by the 8 August 2017 Jiuzhaigou, Sichuan Ms 7.0 earthquake[J]. Seismology and Geology, 2018, 40(1): 232-260. |
| [54] | HU K H, ZHANG X P, YOU Y, et al. Landslides and dammed lakes triggered by the 2017 Ms 6.9 Milin earthquake in the Tsangpo gorge[J]. Landslides, 2019, 16(5): 993-1001. |
| [55] | SHAO X Y, XU C, MA S Y. Preliminary analysis of coseismic landslides induced by the 1 June 2022 Ms 6.1 Lushan earthquake, China[J]. Sustainability, 2022, 14(24): 16554. |
| [56] | FAN X M, YUNUS A P, SCARINGI G, et al. Rapidly evolving controls of landslides after a strong earthquake and implications for hazard assessments[J]. Geophysical Research Letters, 2021, 48: e2020GL090509. |
| [57] | CHEN W, PANAHI M, POURGHASEMI H R. Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modelling[J]. Catena, 2017, 157: 310-324. |
| [58] | PHAM B T, TIEN BUI D, POURGHASEMI H R, et al. Landslide susceptibility assessment in the Uttarakhand area (India) using GIS: a comparison study of prediction capability of naïve Bayes, multilayer perceptron neural networks, and functional trees methods[J]. Theoretical and Applied Climatology, 2017, 128(1): 255-273. |
| [59] | TIEN BUI D, TUAN T A, KLEMPE H, et al. Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree[J]. Landslides, 2016, 13(2): 361-378. |
| [60] | YOUSSEF A M, POURGHASEMI H R, EL-HADDAD B A, et al. Landslide susceptibility maps using different probabilistic and bivariate statistical models and comparison of their performance at Wadi Itwad Basin, Asir Region, Saudi Arabia[J]. Bulletin of Engineering Geology and the Environment, 2016, 75(1): 63-87. |
| [61] | YANG J, HUANG X. 30 m annual land cover and its dynamics in China from 1990 to 2019[J]. Earth System Science Data, 2021, 13(8): 3907-3925. |
| [62] | HALL M A. Correlation-based feature selection for machine learning[D]. Hamilton: The University of Waikato, 1999. |
| [63] | 肖克炎, 李程, 唐瑞, 等. 大数据智能预测评价[J]. 地学前缘, 2025, 32(4): 20-37. |
| [64] | CHEN C, FAN L. Selection of contributing factors for predicting landslide susceptibility using machine learning and deep learning models[J]. Stochastic Environmental Research and Risk Assessment, 2023: 1-26. https://doi.org/10.1007/s00477-023-02556-4. |
| [65] | LIU Z Q, GILBERT G, CEPEDA J M, et al. Modelling of shallow landslides with machine learning algorithms[J]. Geoscience Frontiers, 2021, 12(1): 385-393. |
| [66] | LI W, XU Q, LI Q, et al. Preliminary analysis of the coseismic geohazards induced by the 2023 Jishishan Ms 6.2 earthquake[J]. Journal of Chengdu University of Technology(Science & Technology Edition), 2024, 51(1): 33-45. |
| [67] | VABALAS A, GOWEN E, POLIAKOFF E, et al. Machine learning algorithm validation with a limited sample size[J]. PLoS One, 2019, 14(11): e0224365. |
| [68] | LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444. |
| [69] | MEENA S R, SOARES L P, GROHMANN C H, et al. Landslide detection in the Himalayas using machine learning algorithms and U-Net[J]. Landslides, 2022, 19(5): 1209-1229. |
| [70] | YOUSSEF A M, EL-HADDAD B A, SKILODIMOU H D, et al. Landslide susceptibility, ensemble machine learning, and accuracy methods in the southern Sinai Peninsula, Egypt: assessment and mapping[J]. Natural Hazards, 2024, 120(15): 14227-14258. |
| [71] | YANG D D, QIU H J, YE B F, et al. Distribution and recurrence of warming-induced retrogressive thaw slumps on the central Qinghai-Tibet Plateau[J]. Journal of Geophysical Research: Earth Surface, 2023, 128(8): e2022JF007047. |
| [72] | AI X, SUN B T, CHEN X Z. Construction of small sample seismic landslide susceptibility evaluation model based on Transfer Learning: a case study of Jiuzhaigou earthquake[J]. Bulletin of Engineering Geology and the Environment, 2022, 81(3): 116. |
| [73] | VALIANTE M, GUIDA D, DELLA SETA M, et al. A spatiotemporal object-oriented data model for landslides (LOOM)[J]. Landslides, 2021, 18(4): 1231-1244. |
| [74] | HOANG D A, LE H V, PHAM D V, et al. Hybrid BBO-DE optimized SPAARCTree ensemble for landslide susceptibility mapping[J]. Remote Sensing, 2023, 15(8): 2187. |
| [75] | NEZHAD S K, BAROONI M, VELIOGLU SOGUT D, et al. Ensemble neural networks for the development of storm surge flood modeling: a comprehensive review[J]. Journal of Marine Science and Engineering, 2023, 11(11): 2154. |
| [76] | DE SANTI M, KHAN U T, ARNOLD M, et al. Forecasting point-of-consumption chlorine residual in refugee settlements using ensembles of artificial neural networks[J]. NPJ Clean Water, 2021, 4: 35. |
| [1] | 刘静, 孙照通, 王文鑫, 李云帅, 姚文倩, 崔凤珍, 刘丛强. 表层地球系统的深部过程响应与地表自然灾害[J]. 地学前缘, 2025, 32(3): 7-22. |
| [2] | 徐继山, 彭建兵, 隋旺华, 安海波, 李作栋, 徐文杰, 董培杰. 郯庐断裂转换段新沂地裂缝成生机理及构造意义[J]. 地学前缘, 2024, 31(3): 470-481. |
| [3] | 汤明高, 刘昕昕, 李广, 赵欢乐, 许强, 朱星, 李为乐. 雅鲁藏布江色东普沟冰崩机理试验研究[J]. 地学前缘, 2023, 30(4): 405-417. |
| [4] | 孙东, 杨涛, 曹楠, 覃亮, 胡骁, 魏萌, 蒙明辉, 张伟. 泸定MS 6.8地震同震地质灾害特点及防控建议[J]. 地学前缘, 2023, 30(3): 476-493. |
| [5] | 孙永帅, 胡瑞林. 不同角度基覆面上土石混合体变形试验研究及对滑坡演化的启示[J]. 地学前缘, 2023, 30(3): 494-504. |
| [6] | 陈剑, 陈瑞琛, 崔之久. 高速远程滑坡的地貌学与沉积学研究进展[J]. 地学前缘, 2021, 28(4): 349-360. |
| [7] | 张永双, 刘筱怡, 吴瑞安, 郭长宝, 任三绍. 青藏高原东缘深切河谷区古滑坡:判识、特征、时代与演化[J]. 地学前缘, 2021, 28(2): 94-105. |
| [8] | 陈剑, 崔之久, 陈瑞琛, 郑欣欣. 金沙江上游特米古滑坡堰塞湖成因与演化[J]. 地学前缘, 2021, 28(2): 85-93. |
| [9] | 李德文, 李林林, 马保起, 张健. 湖泊沉积对地震动的响应特征与古地震序列重建[J]. 地学前缘, 2021, 28(2): 232-245. |
| [10] | 王昊, 崔鹏, Paul A.CARLING. 高能洪水沉积研究综述[J]. 地学前缘, 2021, 28(2): 140-167. |
| [11] | 黄小龙, 吴中海, 刘锋, 田婷婷, 黄小巾, 张铎. 滇西北程海断裂带主要古地震滑坡及其分布特征的构造解释[J]. 地学前缘, 2021, 28(2): 125-139. |
| [12] | 王玉峰, 程谦恭, 林棋文, 李坤, 史安文. 青藏高原古高速远程滑坡沉积学特征研究[J]. 地学前缘, 2021, 28(2): 106-124. |
| [13] | 赖忠平, 杨安娜, 丛禄, 刘维明, 王昊. 山地灾害沉积物的测年综述[J]. 地学前缘, 2021, 28(2): 1-18. |
| [14] | 张小林, 苏培东, 苏少凡, 马云长, 杨枫. 龙泉山构造区隧道浅层天然气来源定量研究[J]. 地学前缘, 2020, 27(3): 262-268. |
| [15] | 罗鸿东,李瑞冬,张勃,曹博. 基于信息量法的地质灾害气象风险预警模型:以甘肃省陇南地区为例[J]. 地学前缘, 2019, 26(6): 289-297. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||