地学前缘 ›› 2021, Vol. 28 ›› Issue (3): 87-96.DOI: 10.13745/j.esf.sf.2021.1.10
洪双( ), 左仁广*(), 胡浩, 熊义辉, 王子烨
), 左仁广*(), 胡浩, 熊义辉, 王子烨
收稿日期:2021-01-11
修回日期:2021-01-20
出版日期:2021-05-20
发布日期:2021-05-23
通信作者:
左仁广
作者简介:洪 双(1996—),女,硕士研究生,主要研究方向为地质找矿大数据挖掘。E-mail: 1201911206@cug.edu.cn
基金资助:
HONG Shuang(), ZUO Renguang*(), HU Hao, XIONG Yihui, WANG Ziye
Received:2021-01-11
Revised:2021-01-20
Online:2021-05-20
Published:2021-05-23
Contact:
ZUO Renguang
摘要:
磁铁矿广泛分布在岩浆、热液及沉积等各类矿床中,其地球化学元素组成往往受温度、氧逸度等物理化学条件的影响,能反映矿床形成环境并指示矿床成因类型,是一种重要的勘查指示矿物。自20世纪60年代以来,磁铁矿的主微量元素数据被用来构建不同的判别图,试图来区分矿床的成因类型。然而,由于矿床成因类型的多样性以及同一类型矿床的磁铁矿的主微量元素地球化学组成的复杂性,以往基于少数磁铁矿的主微量元素地球化学成分构建的矿床成因类型判别图存在一定的局限性。基于此,本文收集了前人发表在国内外期刊上的主要矿床类型的磁铁矿的元素地球化学数据(7 388条),初步构建了基于电子探针(EPMA)和激光剥蚀-电感耦合等离子体质谱(LA-ICP-MS)磁铁矿元素地球化学大数据集,建立了基于随机森林算法的矿床成因分类模型,并对磁铁矿主微量元素在矿床成因分类中的重要性做出排序。研究结果表明,基于磁铁矿大数据和机器学习算法构建的判别模型,能有效区分主要矿床类型,整体分类准确度高达95%。由于LA-ICP-MS磁铁矿数据集的测试元素多,分析精度高,使得基于LA-ICP-MS磁铁矿数据集的矿床成因分类模型精度高于基于EPMA数据集,表明磁铁矿中元素种类多少和数据测试精度影响矿床成因分类精度。同时,研究发现V元素在矿床成因分类过程中起到了较为重要的作用。此外,基于大数据和机器学习建立的判别模型对新的磁铁矿数据进行测试,可给出该数据属于每种矿床类型的概率,能有效判别矿床成因类型。
中图分类号:
洪双, 左仁广, 胡浩, 熊义辉, 王子烨. 磁铁矿元素地球化学大数据构建及其在矿床成因分类中的应用[J]. 地学前缘, 2021, 28(3): 87-96.
HONG Shuang, ZUO Renguang, HU Hao, XIONG Yihui, WANG Ziye. Magnetite geochemical big data: Dataset construction and application in genetic classification of ore deposits[J]. Earth Science Frontiers, 2021, 28(3): 87-96.
| 矿床类型 | 数据集数量/条 | |
|---|---|---|
| EPMA | LA-ICP-MS | |
| IOCG | 680 | 490 |
| 斑岩型 | 535 | 1 488 |
| 夕卡岩型 | 511 | 813 |
| VMS | 432 | 11 |
| IOA | 628 | 465 |
| BIF | 61 | 628 |
| Fe-Ti | 66 | 332 |
| Ni-Cu | 198 | 0 |
表1 各类型矿床磁铁矿地球化学数据数量
Table 1 Number of published magnetite EMPA and LA-ICP-MS data records for different types of mineral deposits
| 矿床类型 | 数据集数量/条 | |
|---|---|---|
| EPMA | LA-ICP-MS | |
| IOCG | 680 | 490 |
| 斑岩型 | 535 | 1 488 |
| 夕卡岩型 | 511 | 813 |
| VMS | 432 | 11 |
| IOA | 628 | 465 |
| BIF | 61 | 628 |
| Fe-Ti | 66 | 332 |
| Ni-Cu | 198 | 0 |
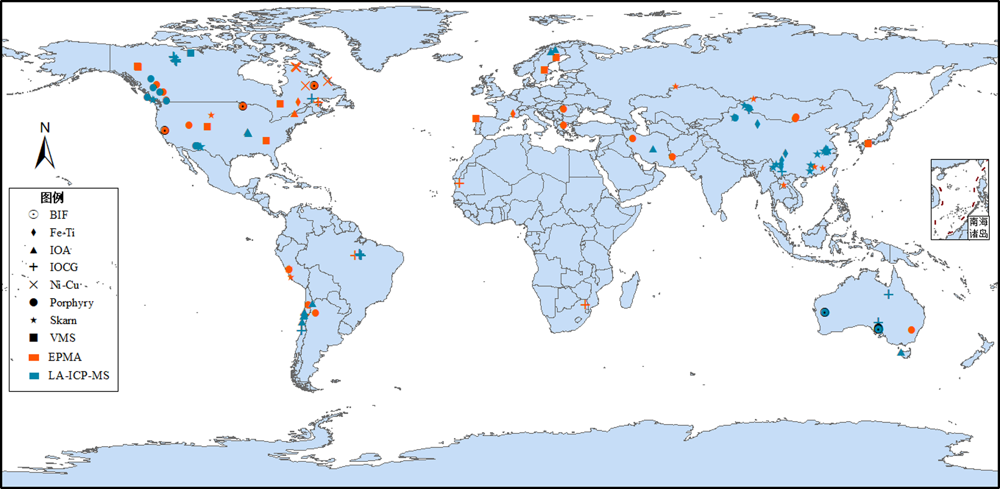
图1 磁铁矿数据集矿床位置分布图
Fig.1 World map showing the locations of the selected ore deposits
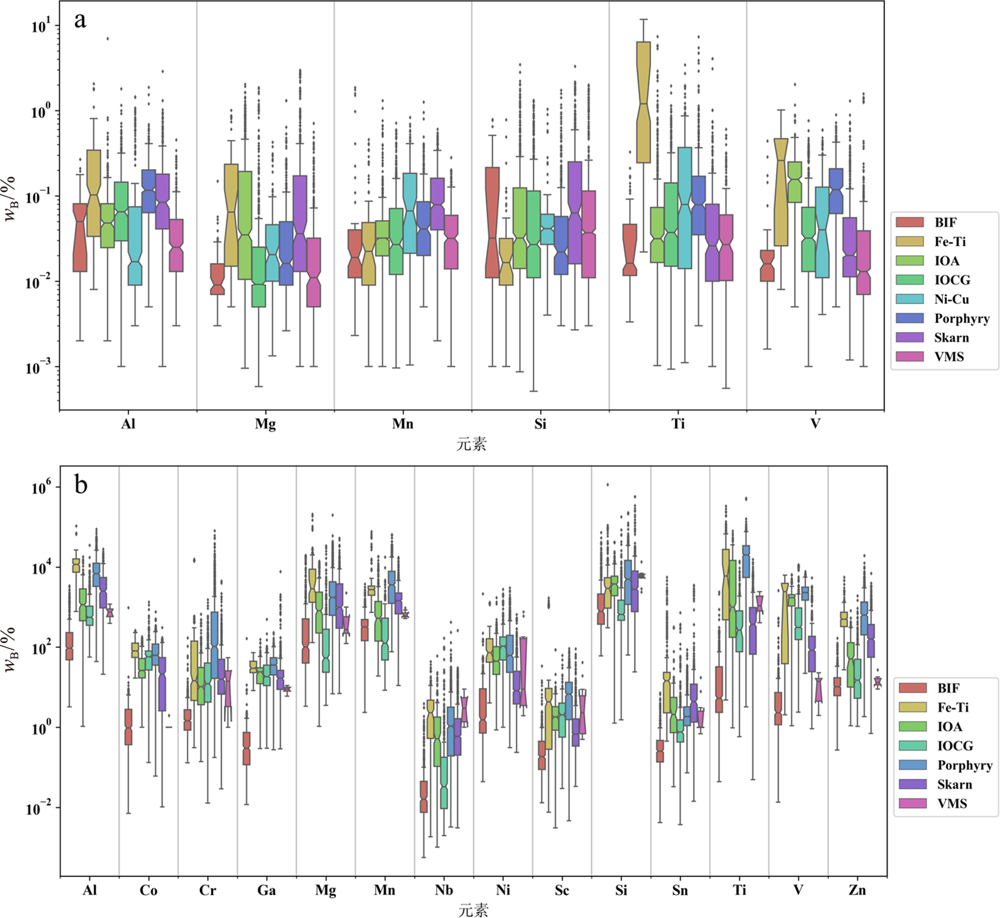
图2 不同矿床类型磁铁矿的EPMA(a)和LA-ICP-MS(b)微量元素槽口箱线图
Fig.2 Boxplot of EPMA (a) and LA-ICP-MS (b) result for trace elements in magnetite from different types of ore deposits
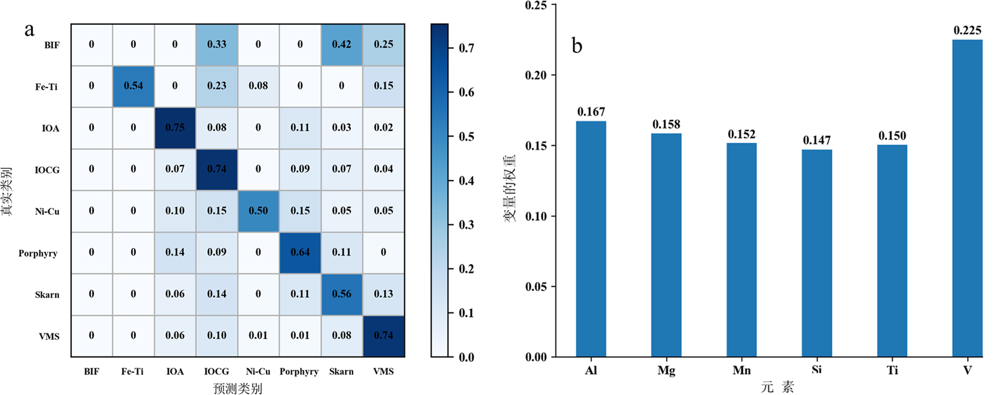
图3 实验方案1中基于EPMA数据的矿床分类准确率(a)和元素重要性(b)
Fig.3 Classification accuracy (a) and element importance (b) based on EPMA data in Experiment 1
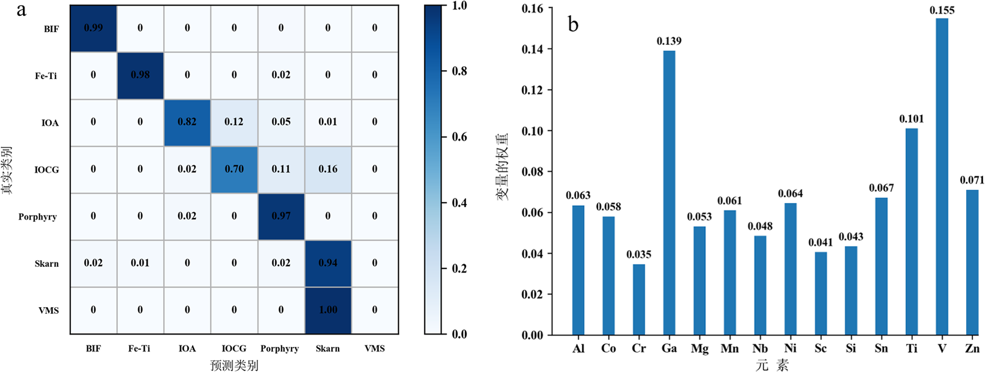
图4 实验方案1基于LA-ICP-MS数据的矿床分类准确率(a)和元素重要性(b)
Fig.4 Classification accuracy (a) and element importance (b) based on LA-ICP-MS data in Experiment 1
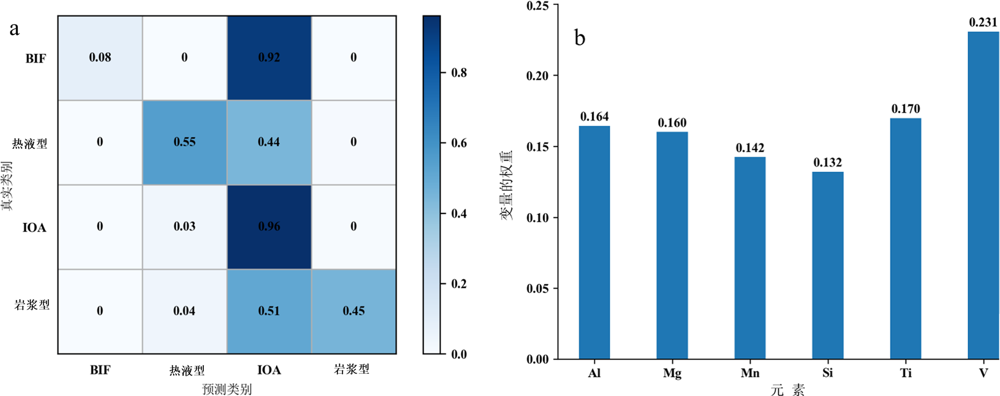
图5 实验方案2基于EPMA数据的矿床分类准确率(a)和元素重要性(b)
Fig.5 Classification accuracy (a) and element importance (b) based on EPMA data in Experiment 2

图6 实验方案2基于LA-ICP-MS数据的矿床分类准确率(a)和元素重要性(b)
Fig.6 Classification accuracy (a) and element importance (b) based on LA-ICP-MS data in Experiment 2
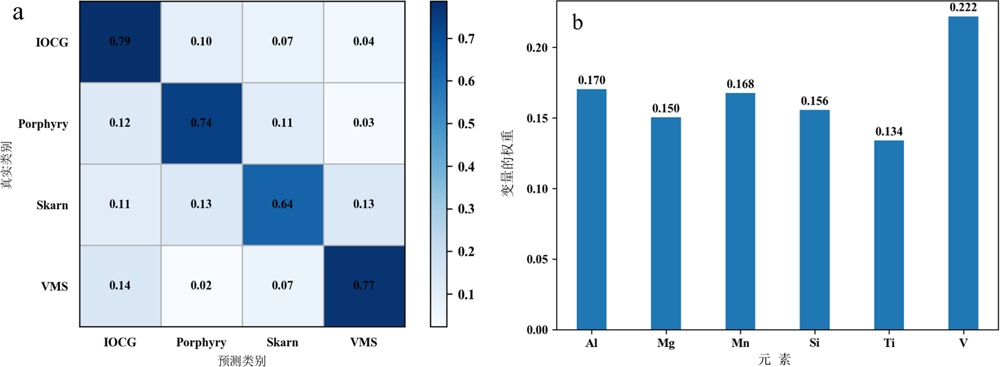
图7 实验方案3基于EPMA数据的矿床分类准确率(a)和元素重要性(b)
Fig.7 Classification accuracy (a) and element importance (b) based on EPMA data in Experiment 3
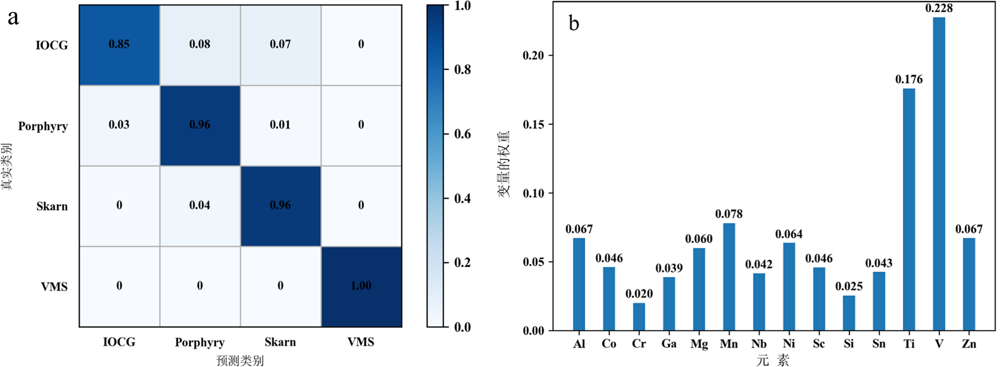
图8 实验方案3基于LA-ICP-MS数据的矿床分类准确率(a)和元素重要性(b)
Fig.8 Classification accuracy (a) and element importance (b) based on LA-ICP-MS data in Experiment 3
| 样本编号 | 各类型矿床的概率 | |||
|---|---|---|---|---|
| BIF | IOA | 热液型 | 岩浆型 | |
| 1 | 0.00 | 0.43 | 0.57 | 0.00 |
| 2 | 0.00 | 0.58 | 0.39 | 0.04 |
| 3 | 0.00 | 0.69 | 0.26 | 0.05 |
| 4 | 0.00 | 0.55 | 0.40 | 0.05 |
| 5 | 0.00 | 0.36 | 0.59 | 0.05 |
| 6 | 0.00 | 0.37 | 0.58 | 0.05 |
| 7 | 0.00 | 0.82 | 0.18 | 0.00 |
| 8 | 0.00 | 0.73 | 0.26 | 0.00 |
| 9 | 0.00 | 0.42 | 0.49 | 0.09 |
| 10 | 0.00 | 0.52 | 0.46 | 0.02 |
| 平均概率 | 0.00 | 0.55 | 0.41 | 0.04 |
表2 Ovalle等[39]EPMA数据的分类结果
Table 2 Classification results based on EPMA data (data from [39])
| 样本编号 | 各类型矿床的概率 | |||
|---|---|---|---|---|
| BIF | IOA | 热液型 | 岩浆型 | |
| 1 | 0.00 | 0.43 | 0.57 | 0.00 |
| 2 | 0.00 | 0.58 | 0.39 | 0.04 |
| 3 | 0.00 | 0.69 | 0.26 | 0.05 |
| 4 | 0.00 | 0.55 | 0.40 | 0.05 |
| 5 | 0.00 | 0.36 | 0.59 | 0.05 |
| 6 | 0.00 | 0.37 | 0.58 | 0.05 |
| 7 | 0.00 | 0.82 | 0.18 | 0.00 |
| 8 | 0.00 | 0.73 | 0.26 | 0.00 |
| 9 | 0.00 | 0.42 | 0.49 | 0.09 |
| 10 | 0.00 | 0.52 | 0.46 | 0.02 |
| 平均概率 | 0.00 | 0.55 | 0.41 | 0.04 |
| 样本编号 | 各类型矿床的概率 | |||
|---|---|---|---|---|
| BIF | IOA | 热液型 | 岩浆型 | |
| 1 | 0.07 | 0.69 | 0.22 | 0.02 |
| 2 | 0.08 | 0.69 | 0.21 | 0.02 |
| 3 | 0.08 | 0.69 | 0.20 | 0.02 |
| 4 | 0.11 | 0.59 | 0.28 | 0.02 |
| 5 | 0.10 | 0.58 | 0.30 | 0.02 |
| 6 | 0.13 | 0.56 | 0.29 | 0.02 |
| 7 | 0.14 | 0.57 | 0.29 | 0.00 |
| 8 | 0.00 | 0.44 | 0.47 | 0.09 |
| 9 | 0.13 | 0.56 | 0.29 | 0.02 |
| 10 | 0.10 | 0.58 | 0.30 | 0.02 |
| 平均概率 | 0.10 | 0.57 | 0.30 | 0.03 |
表3 La Cruz等[40]LA-ICP-MS磁铁矿地球化学数据分类结果
Table 3 Classification results based on LA-ICP-MS data (data from [40])
| 样本编号 | 各类型矿床的概率 | |||
|---|---|---|---|---|
| BIF | IOA | 热液型 | 岩浆型 | |
| 1 | 0.07 | 0.69 | 0.22 | 0.02 |
| 2 | 0.08 | 0.69 | 0.21 | 0.02 |
| 3 | 0.08 | 0.69 | 0.20 | 0.02 |
| 4 | 0.11 | 0.59 | 0.28 | 0.02 |
| 5 | 0.10 | 0.58 | 0.30 | 0.02 |
| 6 | 0.13 | 0.56 | 0.29 | 0.02 |
| 7 | 0.14 | 0.57 | 0.29 | 0.00 |
| 8 | 0.00 | 0.44 | 0.47 | 0.09 |
| 9 | 0.13 | 0.56 | 0.29 | 0.02 |
| 10 | 0.10 | 0.58 | 0.30 | 0.02 |
| 平均概率 | 0.10 | 0.57 | 0.30 | 0.03 |
| [1] |
WARK D A, WATSON E B. TitaniQ: a titanium-in-quartz geothermometer[J]. Contributions to Mineralogy and Petrology, 2006, 152(6):743-754.
DOI URL |
| [2] |
KEITH M, HAASE K M, SCHWARZ-SCHAMPERA U, et al. Effects of temperature, sulfur, and oxygen fugacity on the composition of sphalerite from submarine hydrothermal vents[J]. Geology, 2014, 42(8):699-702.
DOI URL |
| [3] |
REICH M, DEDITIUS A, CHRYSSOULIS S, et al. Pyrite as a record of hydrothermal fluid evolution in a porphyry copper system: a SIMS/EMPA trace element study[J]. Geochimica et Cosmochimica Acta, 2013, 104:42-62.
DOI URL |
| [4] | 金露英, 秦克章, 李光明, 等. 大兴安岭北段岔路口斑岩 Mo-热液脉状Zn-Pb成矿系统硫化物微量元素的分布、起源及其勘探指示[J]. 岩石学报, 2015, 31(8):2417-2434. |
| [5] |
DUPUIS C, BEAUDOIN G. Discriminant diagrams for iron oxide trace element fingerprinting of mineral deposit types[J]. Mineralium Deposita, 2011, 46(4):319-335.
DOI URL |
| [6] | HUANG X W, QI L, MENG Y M. Trace element geochemistry of magnetite from the Fe(-Cu) deposits in the Hami region, Eastern Tianshan Orogenic Belt, NW China[J]. Acta Geologica Sinica-English Edition, 2014, 88(1):176-195. |
| [7] |
NIELSEN R L, FORSYTHE L M, GALLAHAN W E, et al. Major-and trace-element magnetite-melt equilibria[J]. Chemical Geology, 1994, 117(1/2/3/4):167-191.
DOI URL |
| [8] |
DEYELL C L, HEDENQUIST J W. Trace element geochemistry of enargite in the Mankayan district, Philippines[J]. Economic Geology, 2011, 106(8):1465-1478.
DOI URL |
| [9] |
NADOLL P, ANGERER T, MAUK J L, et al. The chemistry of hydrothermal magnetite: a review[J]. Ore Geology Reviews, 2014, 61:1-32.
DOI URL |
| [10] | GHIORSO M S, SACK R O. Thermochemistry of the oxide minerals[J]. Reviews in Mineralogy and Geochemistry, 1991, 25(1):221-264. |
| [11] |
ANDERSON J L, BARTH A P, WOODEN J L, et al. Thermometers and thermobarometers in granitic systems[J]. Reviews in Mineralogy and Geochemistry, 2008, 69(1):121-142.
DOI URL |
| [12] |
BUDDINGTON A F, LINDSLEY D H. Iron-titanium oxide minerals and synthetic equivalents[J]. Journal of Petrology, 1964, 5(2):310-357.
DOI URL |
| [13] | SCHEKA S A, PLATKOV A V, VEZHOSEK A A, et al. The trace element paragenesis of magnetite[M]. Moscow: Nauka, 1980: 147(in Russian). |
| [14] | RAMDOHR P. The ore minerals and their intergrowths[M]. New York: Pergamon Press, 1980. |
| [15] |
LEACH D L, BRADLEY D C, HUSTON D, et al. Sediment-hosted lead-zinc deposits in Earth history[J]. Economic Geology, 2010, 105(3):593-625.
DOI URL |
| [16] |
MALMQVIST D, PARASNIS D S. Aitik: geophysical documentation of a third-generation copper deposit in north Sweden[J]. Geoexploration, 1972, 10(3):149-200.
DOI URL |
| [17] |
MCENROE S A, ROBINSON P, PANISH P T. Aeromagnetic anomalies, magnetic petrology, and rock magnetism of hemo-ilmenite-and magnetite-rich cumulate rocks from the Sokndal Region, South Rogaland, Norway[J]. American Mineralogist, 2001, 86(11/12):1447-1468.
DOI URL |
| [18] |
GREGORY D D, CRACKNELL M J, LARGE R R, et al. Distinguishing ore deposit type and barren sedimentary pyrite using laser ablation-inductively coupled plasma-mass spectrometry trace element data and statistical analysis of large data sets[J]. Economic Geology, 2019, 114(4):771-786.
DOI URL |
| [19] |
NADOLL P, KOENIG A E. LA-ICP-MS of magnetite: methods and reference materials[J]. Journal of Analytical Atomic Spectrometry, 2011, 26(9):1872-1877.
DOI URL |
| [20] | SAVARD D, BARNES S J, DARE S A S, et al. Improved calibration technique for magnetite analysis by LA-ICP-MS[J]. Mineralogical Magazine, 2012, 76(6):2329. |
| [21] |
MÜLLER B, AXELSSON M D, ÖHLANDER B. Trace elements in magnetite from Kiruna, northern Sweden, as determined by LA-ICP-MS[J]. Gff, 2003, 125(1):1-5.
DOI URL |
| [22] | BEAUDOIN G, DUPUIS C. Iron-oxide trace element fingerprinting of mineral deposit types. Exploring for iron oxide copper-gold deposits: Canada and global analogues[R]. In Exploring for iron oxide copper-gold deposits: Canada and global analogues. GAC Short Course Notes, 2009: 107-121. |
| [23] | 黄柯, 朱明田, 张连昌, 等. 磁铁矿LA-ICP-MS分析在矿床成因研究中的应用[J]. 地球科学进展, 2017, 32(3):262-275. |
| [24] | 徐国风, 邵洁涟. 磁铁矿的标型特征及其实际意义[J]. 地质与勘探, 1979, 3:30-37. |
| [25] | 林师整. 磁铁矿矿物化学、成因及演化的探讨[J]. 矿物学报, 1982, 3:166-174. |
| [26] | 陈光远, 孙岱生, 殷辉安. 成因矿物学与找矿矿物学[M]. 重庆: 重庆出版社, 1987. |
| [27] | 王顺金. 论磁铁矿的标型特征[M]. 武汉: 中国地质大学出版社, 1987. |
| [28] |
LOBERG B E H, HORNDAHL A K. Ferride geochemistry of Swedish Precambrian iron ores[J]. Mineralium Deposita, 1983, 18(3):487-504.
DOI URL |
| [29] | SINGOYI B, DANYUSHEVSKY L, DAVIDSON G J, et al. Determination of trace elements in magnetites from hydrothermal deposits using the LA-ICP-MS technique[C]// Keystone: 2006 Conference on Society of Economic Geologists, USA. 2006: 367-368. |
| [30] | 陈华勇, 韩金生. 磁铁矿单矿物研究现状、存在问题和研究方向[J]. 矿物岩石地球化学通报, 2015, 34(4):724-730. |
| [31] |
DARE S A S, BARNES S J, BEAUDOIN G, et al. Trace elements in magnetite as petrogenetic indicators[J]. Mineralium Deposita, 2014, 49(7):785-796.
DOI URL |
| [32] |
BOUTROY E, DARE S A A, BEAUDOIN G, et al. Magnetite composition in Ni-Cu-PGE deposits worldwide: application to mineral exploration[J]. Journal of Geochemical Exploration, 2014, 145:64-81.
DOI URL |
| [33] |
KNIPPING J L, BILENKER L D, SIMON A C, et al. Trace elements in magnetite from massive iron oxide-apatite deposits indicate a combined formation by igneous and magmatic-hydrothermal processes[J]. Geochimica et Cosmochimica Acta, 2015, 171:15-38.
DOI URL |
| [34] |
PISIAK L K, CANIL D, LACOURSE T, et al. Magnetite as an indicator mineral in the exploration of porphyry deposits: a case study in till near the Mount Polley Cu-Au deposit, British Columbia, Canada[J]. Economic Geology, 2017, 112(4):919-940.
DOI URL |
| [35] |
HUANG X W, BOUTROY é, MAKVANDI S, et al. Trace element composition of iron oxides from IOCG and IOA deposits: relationship to hydrothermal alteration and deposit subtypes[J]. Mineralium Deposita, 2019, 54(4):525-552.
DOI URL |
| [36] |
BREIMAN L. Random forests[J]. Machine learning, 2001, 45(1):5-32.
DOI URL |
| [37] | BREIMAN L, CUTLER A. RFtools: for predicting and understanding data[C]. Interface'04 Workshop, 2004. http://oz.berkeley.edu/users/breiman/Random Forests. |
| [38] |
COHEN J. A coefficient of agreement for nominal scales[J]. Educational and Psychological Measurement, 1960, 20(1):37-46.
DOI URL |
| [39] | OVALLE J T, LA CRUZ N L, REICH M, et al. Formation of massive iron deposits linked to explosive volcanic eruptions[J]. Scientific reports, 2018, 8(1):1-11. |
| [40] |
LA CRUZ N L, OVALLE J T, SIMON A C, et al. The geochemistry of magnetite and apatite from the El Laco iron oxide-apatite deposit, Chile: implications for ore genesis[J]. Economic Geology, 2020, 115(7):1461-1491.
DOI URL |
| [41] |
BROUGHM S G, HANCHAR J M, TORNOS F, et al. Mineral chemistry of magnetite from magnetite-apatite mineralization and their host rocks: examples from Kiruna, Sweden, and El Laco, Chile[J]. Mineralium Deposita, 2017, 52(8):1223-1244.
DOI URL |
| [42] |
NYSTROEM J O, HENRIQUEZ F. Magmatic features of iron ores of the Kiruna type in Chile and Sweden: ore textures and magnetite geochemistry[J]. Economic geology, 1994, 89(4):820-839.
DOI URL |
| [43] | NASLUND H R, HENRIQUEZ F, NYSTRÖM J O, et al. Magmatic iron ores and associated mineralisation: examples from the Chilean high Andes and coastal Cordillera[M]. Adelaide: hydrothermal iron oxide copper-gold & related deposits: a global perspective, PGC Publishing, 2002, 2:207-226. |
| [44] |
VELASCO F, TORNOS F, HANCHAR J M. Immiscible iron- and silica-rich melts and magnetite geochemistry at the El Laco volcano (northern Chile): evidence for a magmatic origin for the magnetite deposits[J]. Ore Geology Reviews, 2016, 79:346-366.
DOI URL |
| [45] |
HITZMAN M W, ORESKES N, EINAUDI M T. Geological characteristics and tectonic setting of Proterozoic iron oxide (Cu±U±Au±REE) deposits[J]. Precambrian Research, 1992, 58:241-287.
DOI URL |
| [46] | RHODES A L, ORESKES N, SHEETS S. Geology and rare earth element geochemistry of magnetite deposits at El Laco, Chile[J]. Society of Economic Geologists Special Publication, 1999, 7:299-332. |
| [47] | SILLITOE R H, BURROWS D R. New field evidence bearing on the origin of the El Laco magnetite deposit, northern Chile[J]. Economic Geology, 2002, 97(5):1101-1109. |
| [48] |
HU H, LI J W, HARLOV D E, et al. A genetic link between iron oxide-apatite and iron skarn mineralization in the Jinniu volcanic basin, Daye district, eastern China: evidence from magnetite geochemistry and multi-mineral U-Pb geochronology[J]. Geological Society of America Bulletin, 2020, 132(5/6):899-917.
DOI URL |
| [1] | 姜兆霞, 李三忠, 索艳慧, 吴立新. 海底氢能探测与开采技术展望[J]. 地学前缘, 2024, 31(4): 183-190. |
| [2] | 刘奇鑫, 顾行发, 王春梅, 杨健, 占玉林. 不同尺度的土壤含水量主被动微波联合反演方法研究[J]. 地学前缘, 2024, 31(2): 42-53. |
| [3] | 徐志豪, 闫国英, 杨宗锋, 王昭静, 申俊峰, 张萌萌, 李培培, 徐渴鑫. 白云鄂博矿床磁铁矿成分标型与深部富铁矿体预测[J]. 地学前缘, 2023, 30(2): 426-439. |
| [4] | 侯啸林, 徐继尚, 姜兆霞, 曹立华, 张强, 李广雪, 王双, 翟科. 热带西太平洋沉积物的环境磁学特征对东亚冬季风的响应[J]. 地学前缘, 2022, 29(5): 23-34. |
| [5] | 杨誉博, 苏尚国, 霍延安, 宁亚格, 顾大鹏. 邯邢式铁矿形成机制:来自河北武安斑状二长岩中“含铁熔体-流体”的证据[J]. 地学前缘, 2022, 29(3): 304-318. |
| [6] | 胡义明, 陈腾, 罗序义, 唐超, 梁忠民. 基于机器学习模型的淮河流域中长期径流预报研究[J]. 地学前缘, 2022, 29(3): 284-291. |
| [7] | 刘家军, 翟德高, 王大钊, 高燊, 尹超, 柳振江, 王建平, 王银宏, 张方方. Au-(Ag)-Te-Se成矿系统与成矿作用[J]. 地学前缘, 2020, 27(2): 79-98. |
| [8] | 侯晓阳,苏尚国,杨跃跃. 河北武安玉石洼铁矿中磁铁矿特征及其对铁矿床成因指示意义 [J]. 地学前缘, 2019, 26(6): 244-256. |
| [9] | 洪瑾,甘成势,刘洁. 基于机器学习的洋岛玄武岩主量元素预测稀土元素[J]. 地学前缘, 2019, 26(4): 45-54. |
| [10] | 陈应华,蓝廷广,王洪,唐燕文,戴智慧. 莱芜张家洼铁矿磁铁矿LA-ICP-MS微量元素特征及其对成矿过程的制约[J]. 地学前缘, 2018, 25(4): 32-49. |
| [11] | 郑梦天, 张连昌, 朱明田, 李智泉. 西昆仑喀来子钡铁矿床地质特征、时代及成因探讨[J]. 地学前缘, 2016, 23(5): 252-265. |
| [12] | 邢长明, 王焰, 张传林. 塔里木大火成岩省皮羌层状岩体的矿物结晶顺序和钒钛磁铁矿矿石成因探讨[J]. 地学前缘, 2013, 20(4): 285-298. |
| [13] | 张聚全, 李胜荣, 王吉中, 白明, 卢静, 魏宏飞, 聂潇, 刘海明. 冀南邯邢地区白涧和西石门夕卡岩型铁矿磁铁矿成因矿物学研究[J]. 地学前缘, 2013, 20(3): 76-87. |
| [14] | 郭璇,朱永峰. 新疆西南天山小哈拉军山辉长岩体岩石学及地球化学研究[J]. 地学前缘, 2011, 18(2): 180-190. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||